Caffe Learning Notes(1)
之前一直在学习Transfer Learning,看到DAN和RTN的源代码都是用Caffe写的,所以趁此机会来学习一下Caffe的源代码,为了之后能自己写出来自己的类。
本文在全局上主要参考Caffe Source Code Analysis 这篇博客。这个里面对整个初始化和训练做了一个比较高层次的简单的介绍,可以通读一下来学习基本过程。
接下来还主要参考了不同的学习笔记如下:
后文对这些内容进行了总结和归纳。
Caffe 简介
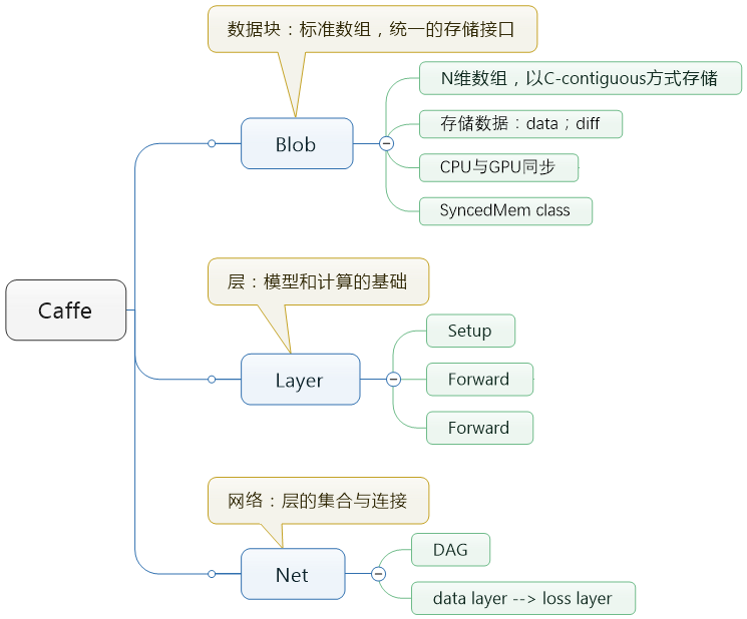
一般在介绍Caffe代码结构的时候,大家都会说Caffe主要由Blob,Layer,Net和Solver这几个部分组成。
Blob主要用来表示网络中的数据,包括训练数据,网络各层自身的参数(包括权值、偏置以及它们的梯度),网络之间传递的数据都是通过Blob来实现的,同时Blob数据也支持在 CPU 与 GPU 上存储,能够在两者之间做同步。Layer是对神经网络中各种层的一个抽象,包括我们熟知的卷积层和下采样层,还有全连接层和各种激活函数层等等。同时每种Layer都实现了前向传播和反向传播,并通过Blob来传递数据。Net是对整个网络的表示,由各种Layer前后连接组合而成,也是我们所构建的网络模型。Solver定义了针对 Net 网络模型的求解方法,记录网络的训练过程,保存网络模型参数,中断并恢复网络的训练过程。自定义Solver能够实现不同的网络求解方式。
总体学习——通过Caffe训练LeNet来看看网络初始化和训练过程
在Caffe提供的例子里,训练LeNet网络的命令为:
cd $CAFFE_ROOT
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt
其中第一个参数build/tools/caffe是Caffe框架的主要框架,由tools/caffe.cpp文件编译而来,第二个参数train表示是要训练网络,第三个参数是 solver 的 protobuf 描述文件。在Caffe中,网络模型的描述及其求解都是通过 protobuf 定义的,并不需要通过敲代码来实现。同时,模型的参数也是通过 protobuf 实现加载和存储,包括 CPU 与 GPU 之间的无缝切换,都是通过配置来实现的,不需要通过硬编码的方式实现。
网络初始化
在caffe.cpp中main函数之外通过RegisterBrewFunction这个宏在每一个实现主要功能的函数之后将这个函数的名字和其对应的函数指针添加到了g_brew_map中,具体分别为train(),test(),device_query(),time()这四个函数。
在运行的时候,根据传入的参数在main函数中,通过GetBrewFunction得到了我们需要调用的那个函数的函数指针,并完成了调用。
在我们上面所说的训练LeNet的例子中,传入的第二个参数为train,所以调用的函数为caffe.cpp中的int train()函数,接下来主要看这个函数的内容。在train函数中有下面两行代码,下面的代码定义了一个指向Solver的shared_ptr。其中主要是通过调用SolverRegistry这个类的静态成员函数CreateSolver得到一个指向Solver的指针来构造shared_ptr类型的solver。而且由于C++多态的特性,尽管solver是一个指向基类Solver类型的指针,通过solver这个智能指针来调用各个成员函数会调用到各个子类(SGDSolver等)的函数。
// caffe.cpp
// 其中输入参数solver_param就是上面所说的第三个参数:网络的模型及求解文件
shared_ptr<caffe::Solver<float> >
solver(caffe::SolverRegistry<float>::CreateSolver(solver_param);
从上面代码可以看出,会先调用父类Solver的构造函数,如下所示。Solver类的构造函数通过Init(param)函数来初始化网络。
//solver.cpp
template <typename Dtype>
Solver<Dtype>::Solver(const SolverParameter& param, const Solver* root_solver)
: net_(), callbacks_(), root_solver_(root_solver),requested_early_exit_(false)
{
Init(param);
}
而在Init(paran)函数中,又主要是通过InitTrainNet()和InitTestNets()函数分别来搭建训练网络结构和测试网络结构。
训练网络只能有一个,在InitTrainNet()函数中首先会设置一些基本参数,包括设置网络的状态为TRAIN,确定训练网络只有一个等,然会会通过net_.reset(new Net<Dtype>(net_param));这条语句新建了一个Net对象。InitTestNets()函数和InitTrainNet()函数基本类似。
上面语句新建了Net对象之后会调用Net类的构造函数,构造函数是通过Init(param)函数来初始化网络结构的。
在net.cpp里init()的主要内容是:其中LayerRegistry<Dtype>::CreateLayer(layer_param)主要是通过调用LayerRegistry这个类的静态成员函数CreateLayer得到一个指向Layer类的shared_ptr类型指针。并把每一层的指针存放在vector<shared_ptr<Layer<Dtype> > > layers_这个指针容器里。这里相当于根据每层的参数layer_param实例化了对应的各个子类层,比如conv_layer(卷积层)和pooling_layer(池化层)。实例化了各层就会调用每个层的构造函数,但每层的构造函数都没有做什么大的设置。
init()函数主要又四个部分组成:
- AppendBottom:设置每一层的输入数据
- AppendTop:设置每一层的输出数据
- layers_[layer_id]->SetUp:对上面设置的输入输出数据计算分配空间,并设置每层的可学习参数(权值和偏置)
- AppendParam:对上面申请的可学习参数进行设置,主要包括学习率和正则率等。
//net.cpp Init()
for (int layer_id = 0; layer_id < param.layer_size(); ++layer_id) {//param是网络参数,layer_size()返回网络拥有的层数
const LayerParameter& layer_param = param.layer(layer_id);//获取当前layer的参数
layers_.push_back(LayerRegistry<Dtype>::CreateLayer(layer_param));//根据参数实例化layer
//下面的两个for循环将此layer的bottom blob的指针和top blob的指针放入bottom_vecs_和top_vecs_,bottom blob和top blob的实例全都存放在blobs_中。相邻的两层,前一层的top blob是后一层的bottom blob,所以blobs_的同一个blob既可能是bottom blob,也可能使top blob。
for (int bottom_id = 0; bottom_id < layer_param.bottom_size();++bottom_id) {
const int blob_id=AppendBottom(param,layer_id,bottom_id,&available_blobs,&blob_name_to_idx);
}
for (int top_id = 0; top_id < num_top; ++top_id) {
AppendTop(param, layer_id, top_id, &available_blobs, &blob_name_to_idx);
}
// 调用layer类的Setup函数进行初始化,输入参数:每个layer的输入blobs以及输出blobs,为每个blob设置大小
layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]);
//接下来的工作是将每层的parameter的指针塞进params_,尤其是learnable_params_。
const int num_param_blobs = layers_[layer_id]->blobs().size();
for (int param_id = 0; param_id < num_param_blobs; ++param_id) {
AppendParam(param, layer_id, param_id);
//AppendParam负责具体的dirtywork
}
}
经过上面的过程,Net类的初始化工作基本就完成了。总体的流程大概就是新建一个Solver对象,然后调用Solver类的构造函数,然后在Solver的构造函数中又会新建Net类实例,在Net类的构造函数中又会新建各个Layer的实例,一直具体到设置每个Blob,大概就介绍完了网络初始化的工作。
训练过程
完成初始化之后,就可以开始对网络经行训练了,开始训练的代码如下所示,指向Solver类的指针solver开始调用Solver类的成员函数Solve(),名称比较绕啊。
// 开始优化
solver->Solve();
Solve函数其实主要就是调用了Solver的另一个成员函数Step()来完成实际的迭代训练过程。
//solver.cpp
template <typename Dtype>
void Solver<Dtype>::Solve(const char* resume_file) {
...
int start_iter = iter_;
...
// 然后调用了'Step'函数,这个函数执行了实际的逐步的迭代过程
Step(param_.max_iter() - iter_);
...
LOG(INFO) << "Optimization Done.";
}
顺着来看看这个Step()函数的主要代码,首先是一个大循环设置了总的迭代次数,在每次迭代中训练iter_size x batch_size个样本,这个设置是为了在GPU的显存不够的时候使用,比如我本来想把batch_size设置为128,iter_size是默认为1的,但是会out_of_memory,借助这个方法,可以设置batch_size=32,iter_size=4,那实际上每次迭代还是处理了128个数据。
//solver.cpp
template <typename Dtype>
void Solver<Dtype>::Step(int iters) {
...
//迭代
while (iter_ < stop_iter) {
...
// iter_size也是在solver.prototxt里设置,实际上的batch_size=iter_size*网络定义里的batch_size,
// 因此每一次迭代的loss是iter_size次迭代的和,再除以iter_size,这个loss是通过调用`Net::ForwardBackward`函数得到的
// accumulate gradients over `iter_size` x `batch_size` instances
for (int i = 0; i < param_.iter_size(); ++i) {
/*
* 调用了Net中的代码,主要完成了前向后向的计算,
* 前向用于计算模型的最终输出和Loss,后向用于
* 计算每一层网络和参数的梯度。
*/
loss += net_->ForwardBackward();
}
...
/*
* 这个函数主要做Loss的平滑。由于Caffe的训练方式是SGD,我们无法把所有的数据同时
* 放入模型进行训练,那么部分数据产生的Loss就可能会和全样本的平均Loss不同,在必要
* 时候将Loss和历史过程中更新的Loss求平均就可以减少Loss的震荡问题。
*/
UpdateSmoothedLoss(loss, start_iter, average_loss);
...
// 执行梯度的更新,这个函数在基类`Solver`中没有实现,会调用每个子类自己的实现
//,后面具体分析`SGDSolver`的实现
ApplyUpdate();
// 迭代次数加1
++iter_;
...
}
}
上面Step()函数主要分为三部分:
loss += net_->ForwardBackward();
这行代码通过Net类的net_指针调用其成员函数ForwardBackward(),其代码如下所示,分别调用了成员函数Forward(&loss)和成员函数Backward()来进行前向传播和反向传播。
// net.hpp
// 进行一次正向传播,一次反向传播
Dtype ForwardBackward() {
Dtype loss;
Forward(&loss);
Backward();
return loss;
}
前面的Forward(&loss)函数最终会执行到下面一段代码,Net类的Forward()函数会对网络中的每一层执行Layer类的成员函数Forward(),而具体的每一层Layer的派生类会重写Forward()函数来实现不同层的前向计算功能。上面的Backward()反向求导函数也和Forward()类似,调用不同层的Backward()函数来计算每层的梯度。
//net.cpp
for (int i = start; i <= end; ++i) {
// 对每一层进行前向计算,返回每层的loss,其实只有最后一层loss不为0
Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
loss += layer_loss;
if (debug_info_) { ForwardDebugInfo(i); }
}
UpdateSmoothedLoss();
这个函数主要做Loss的平滑。由于Caffe的训练方式是SGD,我们无法把所有的数据同时放入模型进行训练,那么部分数据产生的Loss就可能会和全样本的平均Loss不同,在必要时候将Loss和历史过程中更新的Loss求平均就可以减少Loss的震荡问题
ApplyUpdate();
这个函数是Solver类的纯虚函数,需要派生类来实现,比如SGDSolver类实现的ApplyUpdate();函数如下,主要内容包括:设置参数的学习率;对梯度进行Normalize;对反向求导得到的梯度添加正则项的梯度;最后根据SGD算法计算最终的梯度;最后的最后把计算得到的最终梯度对权值进行更新。
template <typename Dtype>
void SGDSolver<Dtype>::ApplyUpdate() {
CHECK(Caffe::root_solver());
// GetLearningRate根据设置的lr_policy来计算当前迭代的learning rate的值
Dtype rate = GetLearningRate();
// 判断是否需要输出当前的learning rate
if (this->param_.display() && this->iter_ % this->param_.display() == 0) {
LOG(INFO) << "Iteration " << this->iter_ << ", lr = " << rate;
}
// 避免梯度爆炸,如果梯度的二范数超过了某个数值则进行scale操作,将梯度减小
ClipGradients();
// 对所有可更新的网络参数进行操作
for (int param_id = 0; param_id < this->net_->learnable_params().size();
++param_id) {
// 将第param_id个参数的梯度除以iter_size,
// 这一步的作用是保证实际的batch_size=iter_size*设置的batch_size
Normalize(param_id);
// 将正则化部分的梯度降入到每个参数的梯度中
Regularize(param_id);
// 计算SGD算法的梯度(momentum等)
ComputeUpdateValue(param_id, rate);
}
// 调用`Net::Update`更新所有的参数
this->net_->Update();
}
等进行了所有的循环,网络的训练也算是完成了。上面大概说了下使用Caffe进行网络训练时网络初始化以及前向传播、反向传播、梯度更新的过程,其中省略了大量的细节。上面还有很多东西都没提到,比如说Caffe中Layer派生类的注册及各个具体层前向反向的实现、Solver派生类的注册、网络结构的读取、模型的保存等等大量内容。