物体检测领域论文概述总结
物体检测领域论文概述总结
图像领域有这么几个重要的问题领域,包括如下的图像分类、物体检测、语义分割、实例分割。
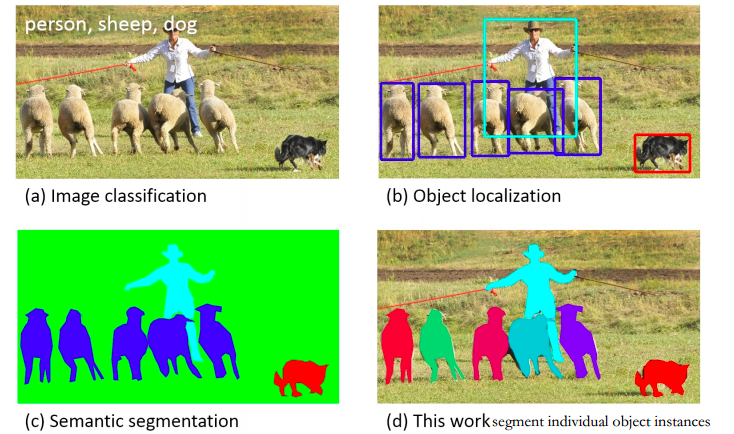
当前,在大数据集上的图像分类已经可以说是达到了非常好的效果了,使用的方法也是非常直观,套用任何一种神经网络都可以得到非常好的效果。典型的验证就是近几年ImageNet比赛已经停办了。
而接下来的几个问题最近几年都有比较好的发展,从多Stage到如今End-to-End的方法,可以说是一条很清晰的脉络。如今最前沿的研究课题就是实例分割。
物体检测
物体检测的难点我引用一段RBG在文中的一段话。
Complexity arises because detection requires the accurate localization of objects, creating two primary challenges. First, numerous candidate object locations (often called “proposals”) must be processed. Second, these candidates provide only rough localization that must be refined to achieve precise localization.
Solutions to these problems often compromise speed, accuracy, or simplicity.
从R-CNN开始,到SPP-Net,Fast R-CNN,Faster R-CNN等一系列工作奠定了这个领域最新最优秀的工作模式。
R-CNN
相比于传统方法,R-CNN是第一次将深度学习引入到目标检测领域的。但是引入的方法还是很初级,很不优雅的。
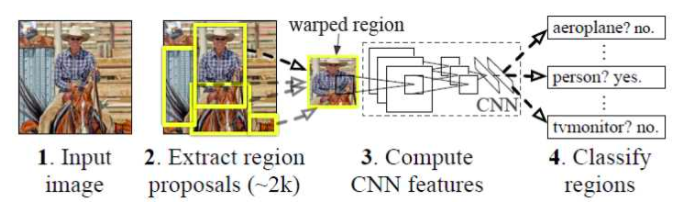
R-CNN算法分为4个步骤:
- 候选区域生成: 一张图像生成1K~2K个候选区域 (采用Selective Search 方法)
- 特征提取: 对每个候选区域,使用深度卷积网络提取特征 (CNN)
- 类别判断: 特征送入每一类的SVM分类器,判别是否属于该类
- 位置精修: 使用回归器精细修正候选框位置
基础知识
Selective Search
使用一种过分割手段,将图像分割成小区域 (1k~2k个)。查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置。输出所有曾经存在过的区域,所谓候选区域。
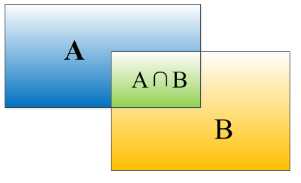
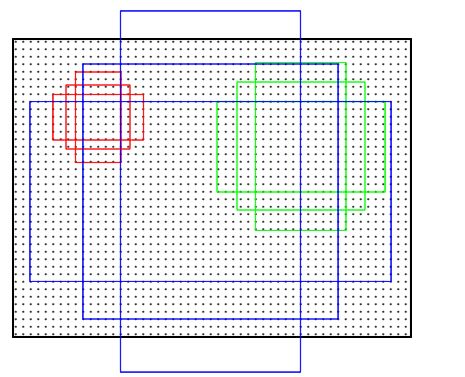
IOU
对于bounding box的定位精度,有一个很重要的概念: 因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。 它定义了两个bounding box的重叠度,如下图所示
非极大值抑制(NMS)
RCNN会从一张图片中找出n个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1) 从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2) 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3) 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。这里不讨论通用的NMS算法,而是用于在目标检测中用于提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
总体思路
首先对每一个输入的图片产生近2000个不分种类的候选区域(region proposals),然后使用CNNs从每个候选框中提取一个固定长度的特征向量(4096维度),接着对每个取出的特征向量使用特定种类的线性SVM进行分类。也就是总个过程分为三个程序:a、找出候选框;b、利用CNN提取特征向量;c、利用SVM进行特征向量分类。
几个问题
输入数据
- 正负样本数量:一张照片我们得到了2000个候选框。然而人工标注的数据一张图片中就只标注了正确的bounding box,我们搜索出来的2000个矩形框也不可能会出现一个与人工标注完全匹配的候选框。因此在CNN阶段我们需要用IOU为2000个bounding box打标签。如果用selective search挑选出来的候选框与物体的人工标注矩形框(PASCAL VOC的图片都有人工标注)的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别(正样本),否则我们就把它当做背景类别(负样本)。
- 图像缩放:Selective Search搜索框搜索出来的图像大小不同,然而CNN对输入图片的大小是有固定的,如果把搜索到的矩形选框不做处理,就扔进CNN中,肯定不行。因此对于每个输入的候选框都需要缩放到固定的大小。文中采用了各向异性缩放,也就是无论比例就直接缩放成固定大小,然后加上了16个像素的padding。

训练阶段
- 使用ImageNet做训练,再使用VOC2007做fine-tunning,以解决数据量不足的问题。Fine-tunning开始的时候,SGD学习率选择0.001,在每次训练的时候,我们batch size大小选择128,其中32个事正样本、96个事负样本。
- CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,在训练的时候最后一层softmax就是分类层。那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低。事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm。
测试阶段
使用selective search的方法在测试图片上提取2000个region propasals ,将每个region proposals归一化到227x227,然后再CNN中正向传播,将最后一层得到的特征提取出来。然后对于每一个类别,使用为这一类训练的SVM分类器对提取的特征向量进行打分,得到测试图片中对于所有region proposals的对于这一类的分数,再使用贪心的非极大值抑制(NMS)去除相交的多余的框。再对这些框进行canny边缘检测,就可以得到bounding-box(then B-BoxRegression)。
作者提到花费在region propasals和提取特征的时间是13s/张-GPU和53s/张-CPU,可以看出时间还是很长的,不能够达到及时性。
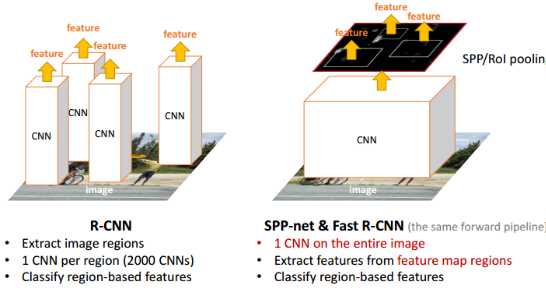
SPP-Net
可以看出来R-CNN虽然引入了CNN,但是使用了很多的stage,同时效率很低。SPP-Net主要改进的就是其中的效率问题。一张图图片会有~2k个候选框,每一个都要单独输入CNN做卷积等操作很费时。SPP-net提出:能否在feature map上提取ROI特征,这样就只需要在整幅图像上做一次卷积。
有两个难点要解决:
- 原始图像的ROI如何映射到特征图(一系列卷积层的最后输出),即原来在一个位置,映射到特征图之后的位置在哪里呢?
- ROI的在特征图上的对应的特征区域的维度不满足全连接层的输入要求怎么办(又不可能像在原始ROI图像上那样进行截取和缩放)?
空间金字塔池化 (Spatial Pyramid Pooling)
So why do CNNs require a fixed input size? A CNN mainly consists of two parts: convolutional layers, and fully-connected layers that follow. The convo- lutional layers operate in a sliding-window manner and output feature maps which represent the spatial arrangement of the activations (Figure 2). In fact, con- volutional layers do not require a fixed image size and can generate feature maps of any sizes. On the other hand, the fully-connected layers need to have fixed- size/length input by their definition. Hence, the fixed- size constraint comes only from the fully-connected layers, which exist at a deeper stage of the network.
也就是说主要是全连接层需要保证固定长度的输入,所以主要的解决办法如下:
- 想办法让不同尺寸的图像也可以使最后一层池化层产生固定的输出维度。(打破图像输入的固定性)
- 想办法让全连接层(罪魁祸首)可以接受非固定的输入维度。(打破全连接层的固定性,继而也打破了图像输入的固定性)
以上的方法1就是SPPnet的思想。方法2其实就是全连接转换为全卷积,作用的效果等效为在原始图像做滑窗,多个窗口并行处理。
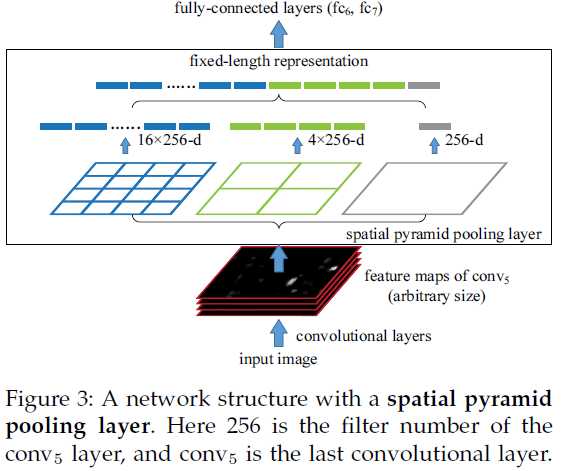
SPP是BOW的扩展,将图像从精细空间划分到粗糙空间,之后将局部特征聚集。在CNN成为主流之前,SPP在检测和分类的应用比较广泛。
假设原图输入是224x224,对于conv5出来后的输出是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。如果像上图那样将reponse map分成1x1(金字塔底座),2x2(金字塔中间),4x4(金字塔顶座)三张子图,分别做max pooling后,出来的特征就是(16+4+1)x256 维度。如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256维度。这样就实现了不管图像尺寸如何 池化n 的输出永远是 (16+4+1)x256 维度。达到不仅可对任意长宽比的图像进行处理,而且可对任意尺度的图像进行处理。
简单来说,就是原来的池化操作一般是规定了pooling size,但是这里的池化操作是规定了输出的size,即pooling size根据最后一层filter的大小而该表。
具体来说,如何保证输出的大小确定呢?如下,所以其中某些部分可能是会重叠的。
With a pyramid level of n×n bins, we implement this pooling level as a sliding window pooling, where the window size win = ⌈a/n⌉ and stride str = ⌊a/n⌋ with ⌈·⌉ and ⌊·⌋ denoting ceiling and floor operations.
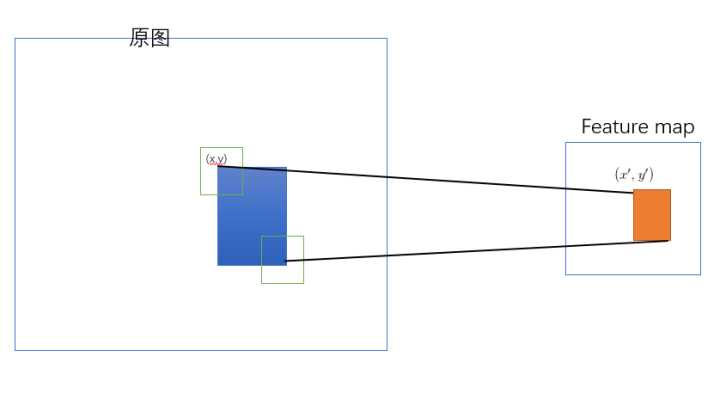
对于难点1,作者对卷积层可视化发现:输入图片的某个位置的特征反应在特征图上也是在相同位置。基于这一事实,对某个ROI区域的特征提取只需要在特征图上的相应位置提取就可以了。具体的提取办法见https://zhuanlan.zhihu.com/p/24780433

SPP-net是把原始ROI的左上角和右下角 映射到 feature map上的两个对应点。 有了feature map上的两队角点就确定了 对应的 feature map 区域(下图中橙色)。
左上角的点(x,y)映射到 feature map上的(x’,y’) : 使得 (x’,y’) 在原始图上感受野(上图绿色框)的中心点 与(x,y)尽可能接近。
一张任意尺寸的图片,在最后的卷积层conv5可以得到特征图。根据Region proposal步骤可以得到很多候选区域,这个候选区域可以在特征图上找到相同位置对应的窗口,然后使用SPP,每个窗口都可以得到一个固定长度的输出。将这个输出输入到全连接层里面。这样,图片只需要经过一次CNN,候选区域特征直接从整张图片特征图上提取。在训练这个特征提取网络的时候,使用分类任务得到的网络,固定前面的卷积层,只微调后面的全连接层。
几个问题
- training is a multi-stage pipeline that involves extracting features, fine-tuning a network with log loss, training SVMs, and finally fitting bounding-box regressors.
- Features are also written to disk.
- Unlike R-CNN, the fine-tuning algorithm proposed in cannot update the convolutional layers that precede the spatial pyramid pooling. Unsurprisingly, this limitation (fixed convolutional layers) limits the accuracy of very deep networks.
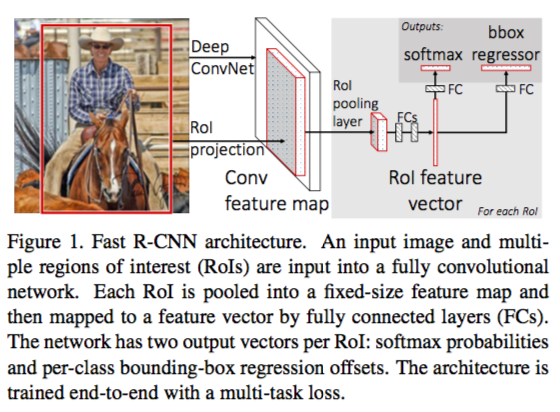
Fast R-CNN
Fast R-CNN 几大主要贡献点 :
-
实现大部分end-to-end训练(提proposal阶段除外): 所有的特征都暂存在显存中,就不需要额外的磁盘空。
joint training (SVM分类,bbox回归 联合起来在CNN阶段训练)把最后一层的Softmax换成两个,一个是对区域的分类Softmax(包括背景),另一个是对bounding box的微调。
这个网络有两个输入,一个是整张图片,另一个是候选proposals算法产生的可能proposals的坐标。(对于SVM和Softmax,论文在SVM和Softmax的对比实验中说明,SVM的优势并不明显,故直接用Softmax将整个网络整合训练更好。对于联合训练: 同时利用了分类的监督信息和回归的监督信息,使得网络训练的更加鲁棒,效果更好。这两种信息是可以有效联合的。)
-
提出了一个RoI层,算是SPP的变种,SPP是pooling成多个固定尺度,RoI只pooling到单个固定的尺度 (论文通过实验得到的结论是多尺度学习能提高一点点mAP,不过计算量成倍的增加,故单尺度训练的效果更好。)ROI的选取机制和SPP中的机制相同,也是有重叠的pooling。
-
文中分析了SPPNet和RCNN中为何反向传播慢,是因为每次的sample都是从不同的images中抽取的,例如128个样本,就要有128次前馈和反馈。文中提出了一种的方法,是使用少的batch size,即选取少的images,每次在image中sample多个训练数据。For example, when using N = 2 and R = 128, the proposed training scheme is roughly 64× faster than sampling one RoI from 128 different images (i.e., the R-CNN and SPPnet strategy). 作者担心这种方法可能会因为sample相关性大而效果不好,但是实际情况中并未出现。
Tricks
-
论文在回归问题上并没有用很常见的2范数作为回归,而是使用所谓的鲁棒L1范数作为损失函数。
该函数在 (−1,1) 之间为二次函数,而其他区域为线性函数,作者表示这种形式可以增强模型对异常数据的鲁棒性。
-
论文发现由于输入的ROI个数很多,其中一半的forward的时间都花在了全连接层上,所以将比较大的全连接层用SVD分解了一下使得检测的时候更加迅速。
Bounding-box Regression
有了ROI Pooling层其实就可以完成最简单粗暴的深度对象检测了,也就是先用selective search等proposal提取算法得到一批box坐标,然后输入网络对每个box包含一个对象进行预测,此时,神经网络依然仅仅是一个图片分类的工具而已,只不过不是整图分类,而是ROI区域的分类,显然大家不会就此满足,那么,能不能把输入的box坐标也放到深度神经网络里然后进行一些优化呢?
在Fast-RCNN中,有两个输出层:第一个是针对每个ROI区域的分类概率预测 p=(p0,p1,…,pK),第二个则是针对每个ROI区域坐标的偏移优化t^k=(t^k_x,t^k_y,t^k_w,t^k_h) , 0<= k <= K是多类检测的类别序号。
整体使用了multi-task loss,其中第一项是类别正确与否的log误差,第二项是box的误差,[u>=1] 是为了表示排除背景的box loss。
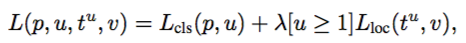
这里我们着重介绍第二部分中的L_loc,即坐标偏移优化。
假设对于类别 k*,在图片中标注了一个groundtruth坐标: t* ,而预测值为t,二者理论上越接近越好。
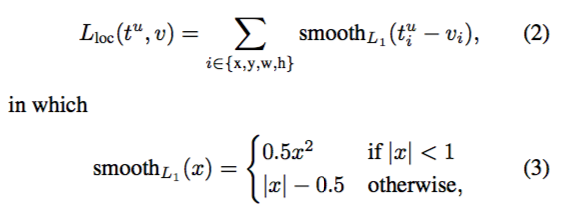
这种loss相比于L2来说,在相差特别大的时候做了一个简化,使得当box unbounded的时候,对于gradient不会特别敏感。
贡献点
- 本文第一次实现了端到端的训练和测试,同时把分类和回归两者结合起来,使得特征能够同时学习两种问题。
- 在速度上提出了包括单层ROI pooling layer,Truncated SVD缩减fc层和小batch number多sample等方法加快速度。
- 探究了关于fine-tunning的范围。首先,并非只fine-tunning全连接层,前面的conv也要。”training through the RoI pooling layer is important for very deep nets.”。但是也并非所有层都需要,最前面的例如conv1也可以freeze。”For VGG16, we found it only necessary to update layers from conv3_1 and up。”
- 实验证明
- multi-task learning,也就是同时学习类别和bounding-box是更好的。
- 使用多个scale的数据来训练是没有必要的,虽然有小幅的map提升,但是计算量也大幅增加。
- 更多的数据带来更好的效果。
- 直接使用softmax比使用SVM更好。
- 并非proposal数量越多越好。
疑点
-
如何将图像和proposal的坐标同时输入到网络中来进行训练呢?
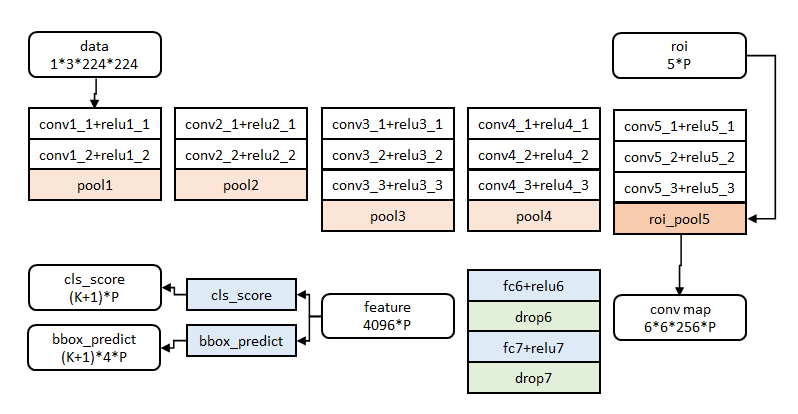 通过这个图可以看出来,图像是在一开始就输入的,但是roi的五个值(image_id, x, y, height, width)是在conv部分之后输入的。
通过这个图可以看出来,图像是在一开始就输入的,但是roi的五个值(image_id, x, y, height, width)是在conv部分之后输入的。 -
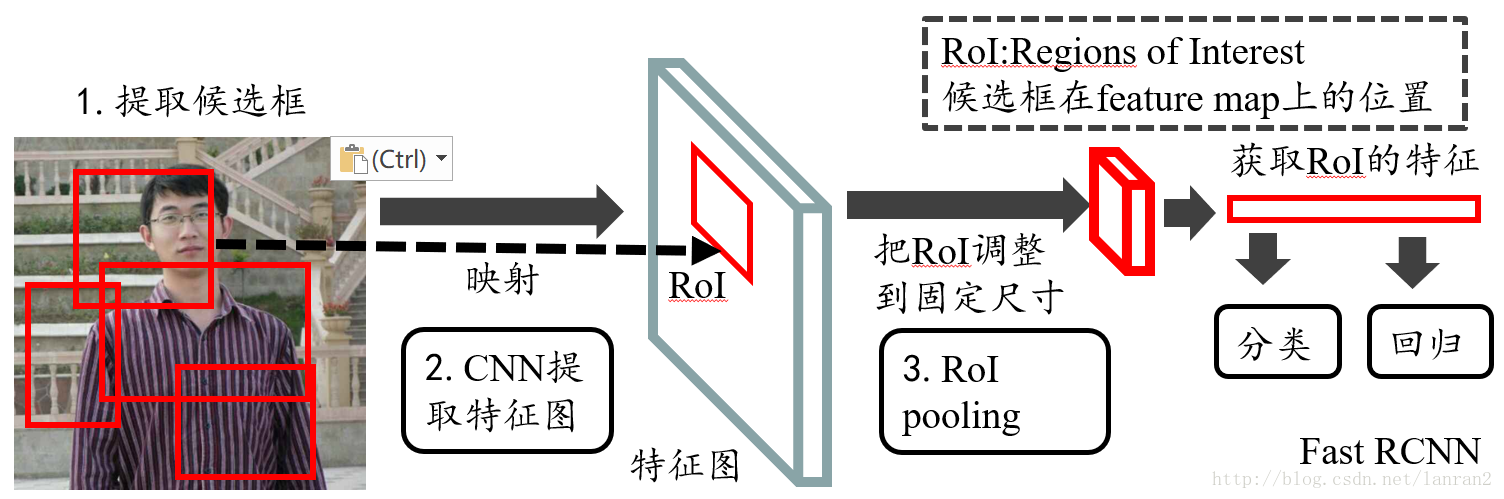
ROI pooling layer是怎么实现的
reference:ROI Pooling层解析.
输入有两部分组成:- 特征图:指的是图1中所示的特征图,在Fast RCNN中,它位于RoI Pooling之前,在Faster RCNN中,它是与RPN共享那个特征图,通常我们常常称之为“share_conv”;
- rois:在Fast RCNN中,指的是Selective Search的输出;在Faster RCNN中指的是RPN的输出,一堆矩形候选框框,形状为1x5x1x1(4个坐标+索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)
输出是batch个vector,其中batch的值等于RoI的个数,vector的大小为channel * w * h;RoI Pooling的过程就是将一个个大小不同的box矩形框,都映射成大小固定(w * h)的矩形框;
YOLO
YOLO核心思想:从R-CNN到Fast R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但是速度还不行。 YOLO提供了另一种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
YOLO的主要特点:
- 速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
- 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
- 泛化能力强。
整体流程:
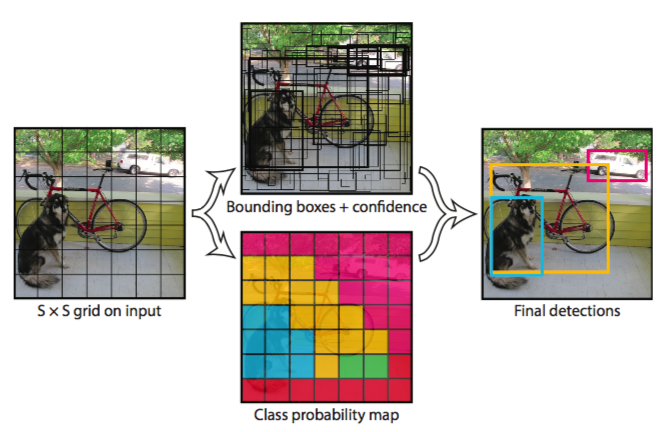
- Resize成448*448,图片分割得到7*7网格(cell)
- CNN提取特征和预测:卷积不忿负责提特征。全链接部分负责预测:
- a) 7*7*2=98个bounding box(bbox) 的坐标x_{center},y_{center},w,h 和是否有物体的confidence。
- b) 7*7=49个cell所属20个物体的概率。
- 过滤bbox(通过nms)
训练过程
使用的loss function如下:

Note that the loss function only penalizes classification error if an object is present in that grid cell (hence the conditional class probability discussed earlier). It also only penalizes bounding box coordinate error if that predictor is “responsible” for the ground truth box (i.e. has the highest IOU of any predictor in that grid cell).
其中特别的,还将lambda_coord提高(=5),lambda_noobj减小(=0.5),这样是为了减少有物体时的gradient过分变大,从而增加模型的稳定性,更好的收敛。原文如是说:“Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.”
除此之外,在训练中还特意使用了learning rate先增后减的方法,而避免收敛到不稳定的gradient处。
缺陷:
- YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。针对不同大小的物体的loss相同,但是同样的偏移对于不同大小的物体影响程度不同。
Faster R-CNN
Faster R-CNN可以看作RPN+Fast R-CNN。主要的改进就是将ss生成proposal部分改成了RPN生成proposal,同时proposal是可以end-to-end来学习的。所以主要有三个问题要解决:
- 如何设计区域生成网络
- 如何训练区域生成网络;
- 如何让区域生成网络和Fast RCNN网络共享特征提取网络。
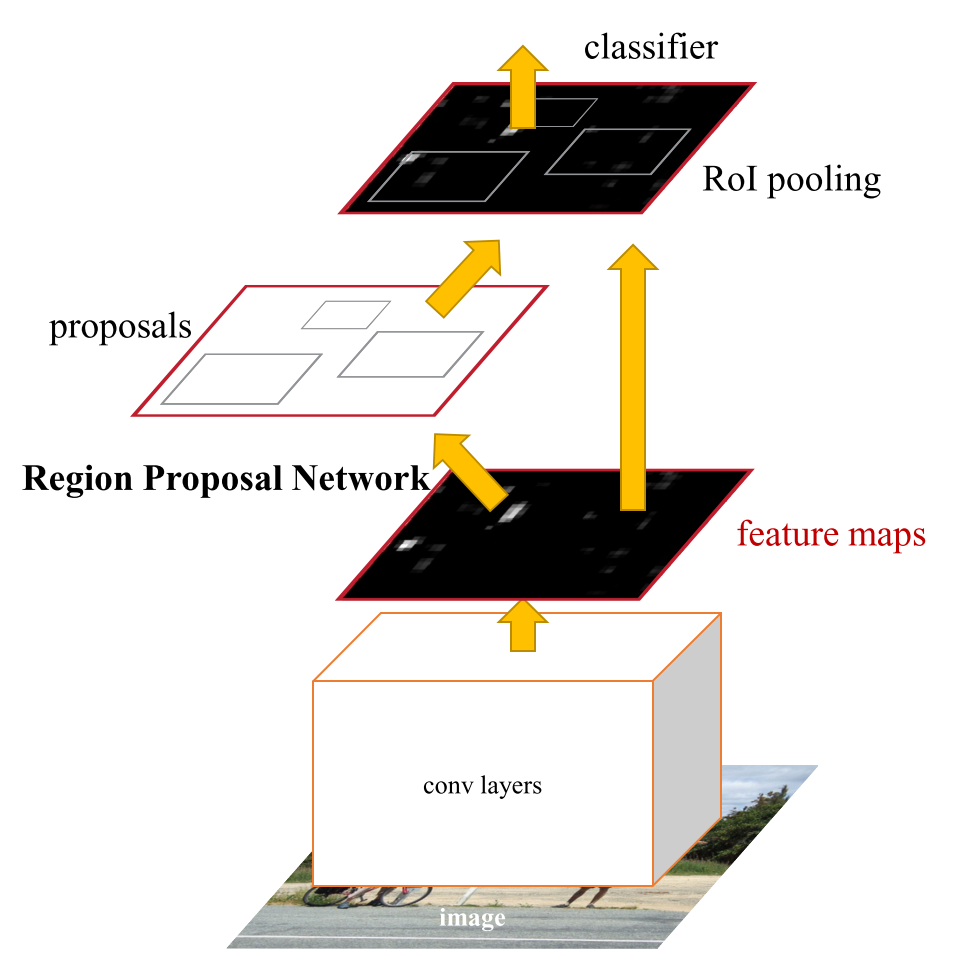
RPN Network
在Faster R-CNN之前的two-stage模型的主要时间瓶颈在proposal部分,这也是Region Proposal Network提出的主要原因。RPN是一个FCN型网络,输出包括候选区域的分数(是object和不是object的score)和代表proposal位置的四个参数(four coordinates)。
Pyramid of regression references (“anchor” boxes)
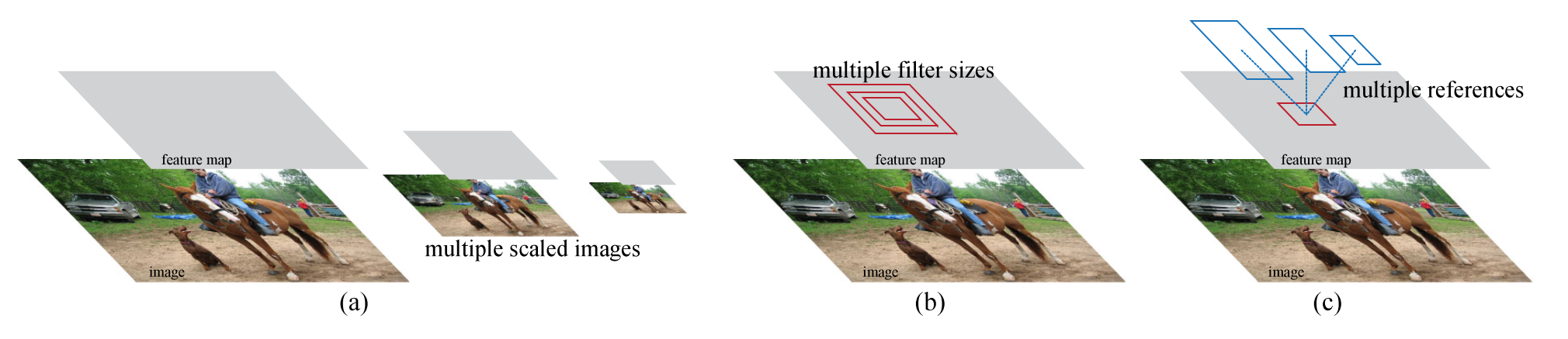
为了能够对图片中不同scale和size的目标进行识别,有上述几种常见的方法。第一种是在SPP Net等网络中使用的,就是生成不同尺寸的输入图片,然后再使用同样的feature map来处理,称为pyramid of images and feature maps;第二种是在feature map上使用不同scale和size的filter;第三种是在在regression问题中使用多个参考box。第一种的效果不错,但是显然最大的问题是计算量的倍增;第二种方法是在sliding window的时候就使用多种filter,一般和第一种方法配合在一起;第三种方法也就是本文的方法,优势在于仅在一种size的输入图片上使用一种size的filter,文中也对集中方法进行了比对,可以参考原文。
这种multi-scale的设计是减少计算量的关键。
Anchor
针对上述的这个pyramid方法,本文使用了类似如下的anchor boxes。
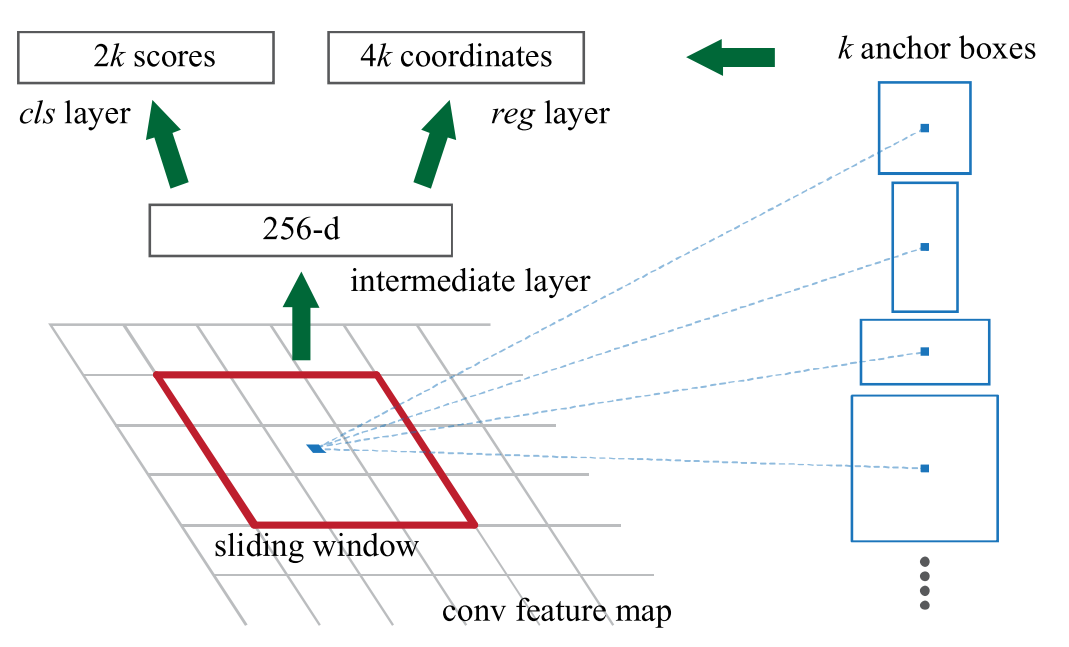
在前面共有的conv部分的最后一层,使用3*3的滑动窗来遍历整个feature map,对于每个位置,使用k个anchor来输出对应的score和coordinate。为何要做Bounding-box regression呢?因为可以得到不同比例大小的bounding box,增加IoU。
有了这样的anchor之后最重要的特点在于translation invariant。得益于使用了sliding window对整个feature map都进行了这些anchor box的输出,所以无论object在哪里都并无差异。
anchor的大小是针对原始图像而言的,在计算时还要对应到此时的feature map上。
Loss function
针对RPN网络的两个输出,制定了如下的loss
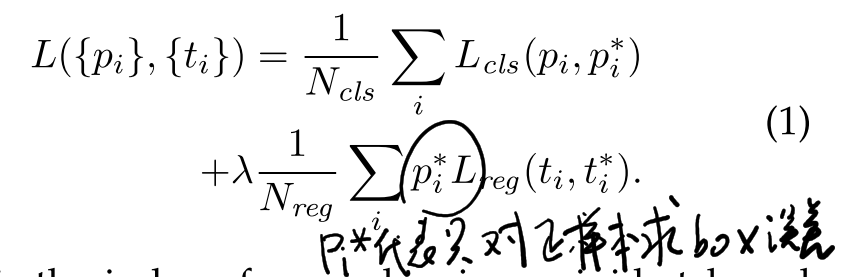
这里的loss function包括了对分类score的误差和regression 位置的误差。值得注意的是在训练过程中,定义了一个anchor只要和object的IoU很大(>0.7)或者是具有最大的IoU就会标记为正样本,所以同一个object可能有多个anchor对应;同时定义了当IoU很小(<0.3)定义为负样本。初次之外的样本是不用于训练的。同时,在loss function中,位置的错误误差也只应用于正样本之上。
note:1)L_reg的计算也使用了前文提到的Smooth L1;2)lambda的值在很大范围内其实是insensitive的;3)针对每种不同scale和size的anchor,都有单独的regressor单独训练。
Training
RPN training
RPN的训练并不是采取固定正负样本比例的方法,而是随机选取256个样本,正样本最多128个,如果正样本不足,就用负样本填充。
Alternating Training
- 使用ImageNet训练好的模型初始化整体的Fast R-CNN部分并固定参数,然后训练RPN;
- 固定RPN的参数,单独训练Fast R-CNN部分;
- 使用第二步中学习好的detector部分来初始化网络,再单独fine tuning RPN,shared conv部分freeze;
- 固定shared conv部分和RPN部分,单独fine-tuning Detector部分。
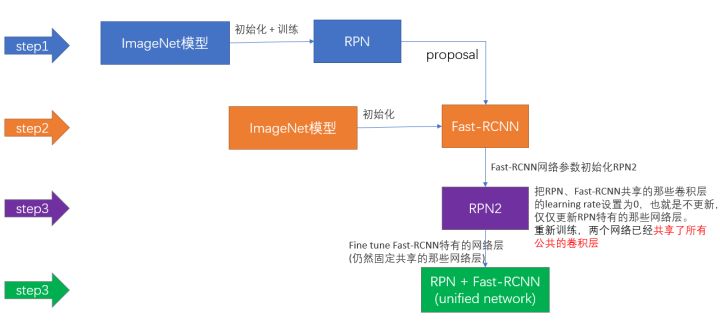
文中发现其实同时学习两个网络也是可以的,但是这种时候忽略了Detector中proposal是RPN输出来的,所以如果不使用严格的推导,只能使用approximate的joint training,但是作者提到这样的效果也是不错的,而且节省了训练时间。
Details
- 输入图片rescale到短边600px;
- 使用128*128,256*256,512*512三种size,1:1 1:2 2:1三种ratio。
- 训练中忽略了所有与object便于有交叉的anchor,否则这些anchor会带来一些非常难学的误差项,使得训练难以收敛。
- 最终使用了NMS减少proposal,同时之后也只选取了top-k个proposal区域进行检测。