SSD论文笔记
SSD(single shot multibox detector)
基于“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列(R-CNN、SPPnet、Fast R-CNN 以及 Faster R-CNN),取得了非常好的结果,但是在速度方面离实时效果还比较远在提高 mAP 的同时兼顾速度,逐渐成为 Object Detection 未来的趋势。 YOLO 虽然能够达到实时的效果,但是其 mAP 与刚面提到的 state of art 的结果有很大的差距。 YOLO 有一些缺陷:每个网格只预测一个物体,容易造成漏检;对于物体的尺度相对比较敏感,对于尺度变化较大的物体泛化能力较差。针对 YOLO 中的这些不足,该论文提出的方法 SSD 在这两方面都有所改进,同时兼顾了 mAP 和实时性的要求。在满足实时性的条件下,接近 state of art 的结果。对于输入图像大小为 300*300 在 VOC2007 test 上能够达到 58 帧每秒( Titan X 的 GPU ),72.1% 的 mAP。输入图像大小为 500 *500 , mAP 能够达到 75.1%。作者的思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。
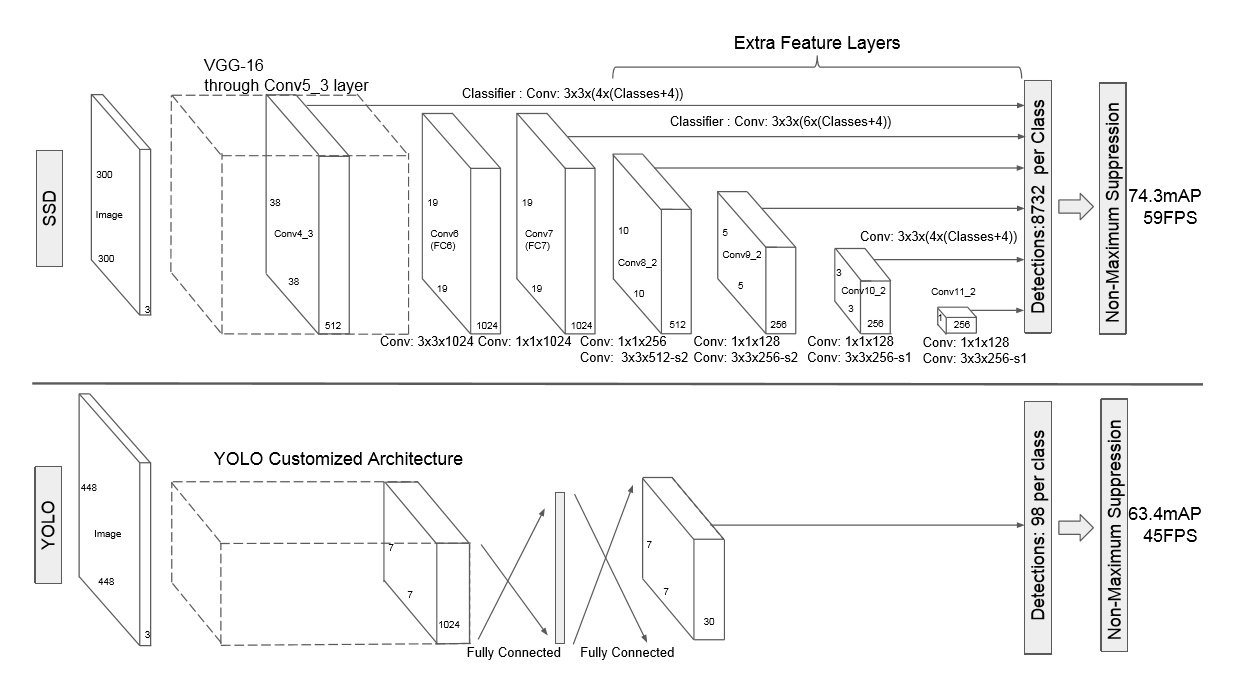
网络结构
该论文采用 VGG16 的基础网络结构,使用前面的前 5 层,然后利用 astrous 算法将 fc6 和 fc7 层转化成两个卷积层。再格外增加了 3 个卷积层,和一个 average pool层。不同层次的 feature map 分别用于 default box 的偏移以及不同类别得分的预测(惯用思路:使用通用的结构(如前 5个conv 等)作为基础网络,然后在这个基础上增加其他的层),最后通过 nms得到最终的检测结果。
这些增加的卷积层的 feature map 的大小变化比较大,允许能够检测出不同尺度下的物体: 在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。观察YOLO,后面存在两个全连接层,全连接层以后,每一个输出都会观察到整幅图像,并不是很合理。但是SSD去掉了全连接层,每一个输出只会感受到目标周围的信息,包括上下文。这样来做就增加了合理性。并且不同的feature map,预测不同宽高比的图像,这样比YOLO增加了预测更多的比例的box。
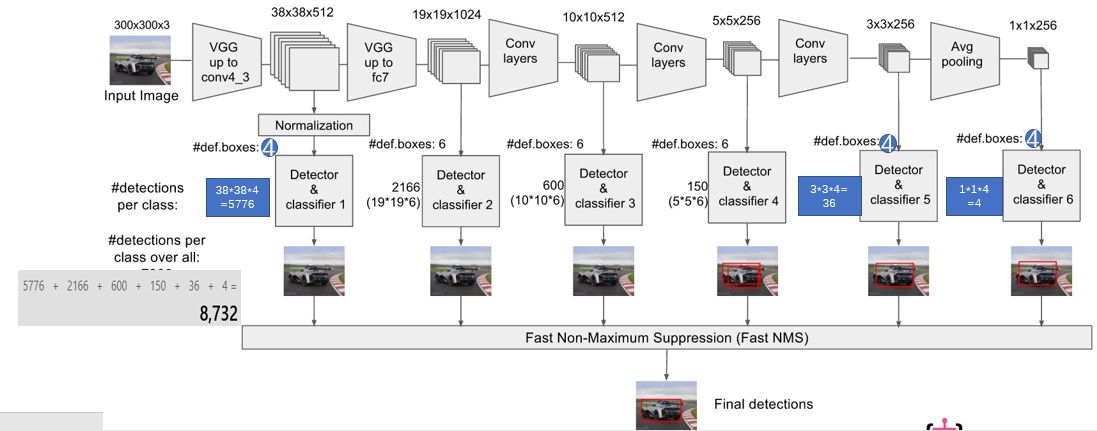
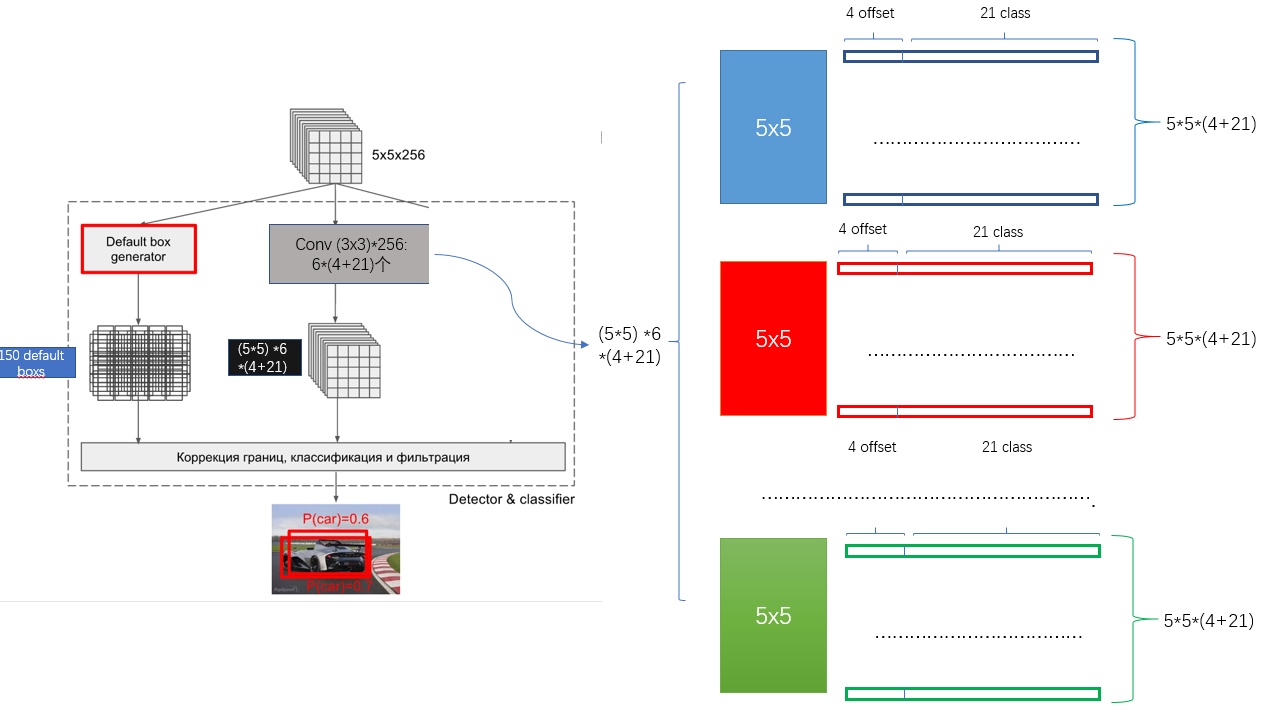
从上图可以看到,对于每个阶段的feature map,都是用了多种不同scale和ratio的bounding box来进行预测回归,使得能够在不同尺度上进行多种检测。同时,每个feature map的输出都是4个位置偏移和21个类别score,即输出是(4+21)维,以下图中5*5*256的这个feature map为例,进行3*3的卷积(padding=1),输出也是同样的大小,对于每个点,都是用了6个default boxes,所以总共是5*5*6个boxes,对应的输出就是5*5*6*(4+21)个输出。这种结构和faster r-cnn中的anchor的结构非常类似。
Training
对于这种end-to-end模型的训练,主要要弄清楚几个问题:如何确定正负样本即对应训练比例;训练的目标函数;Default Boxes如何设置等。
训练样本
-
如何确定正负样本?
给定输入图像以及每个物体的 ground truth,首先找到每个ground true box对应的default box中IOU最大的作为(与该ground true box相关的匹配)正样本。然后,在剩下的default box中找到那些与任意一个ground truth box 的 IOU 大于 0.5的default box作为(与该ground true box相关的匹配)正样本。 一个 ground truth 可能对应多个 正样本default box 而不再像MultiBox那样只取一个IOU最大的default box。其他的作为负样本(每个default box要么是正样本box要么是负样本box)。下图的例子是:给定输入图像及 ground truth,分别在两种不同尺度(feature map 的大小为 88,44)下的匹配情况。有两个 default box 与猫匹配(88),一个 default box 与狗匹配(44)。
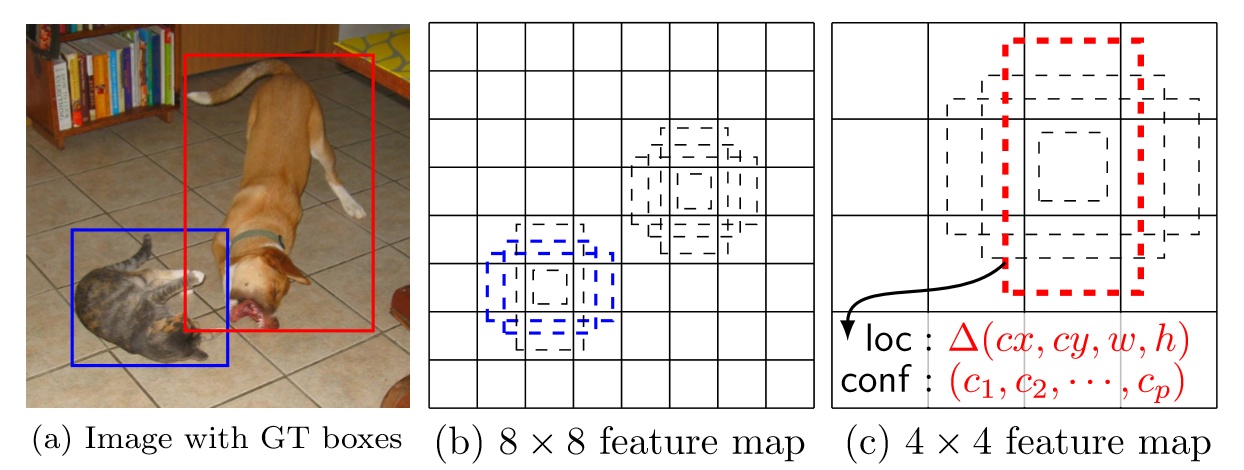
-
如何维持训练样本的平衡?
用于预测的 feature map 上的每个点都对应有 6 个不同的 default box,绝大部分的 default box 都是负样本,导致了正负样本不平衡。在训练过程中,采用了 Hard Negative Mining 的策略(根据confidence loss对所有的box进行排序,使正负例的比例保持在1:3) 来平衡正负样本的比率。这样做能提高4%左右。
-
data augmentation
为了模型更加鲁棒,需要使用不同尺寸的输入和形状,作者对数据进行了如下方式的随机采样
- 使用整张图片
- 使用IOU和目标物体为0.1, 0.3,0.5, 0.7, 0.9的patch (这些 patch 在原图的大小的 [0.1,1] 之间, 相应的宽高比在[1/2,2]之间)
-
随机采取一个patch
当 ground truth box 的 中心(center)在采样的 patch 中时,我们保留重叠部分。在这些采样步骤之后,每一个采样的 patch 被 resize到固定的大小,并且以 0.5 的概率随机的 水平翻转(horizontally flipped)。用数据增益通过实验证明,能够将数据mAP增加8.8%。
目标函数
目标函数,和常见的 Object Detection 的方法目标函数相同,分为两部分:计算相应的 default box 与目标类别的 score(置信度)以及相应的回归结果(位置回归)。置信度是采用 Softmax Loss(Faster R-CNN是log loss),位置回归则是采用 Smooth L1 loss (与Faster R-CNN一样采用 offset_PTDF靠近 offset_GTDF的策略:jian’xia’tu)。
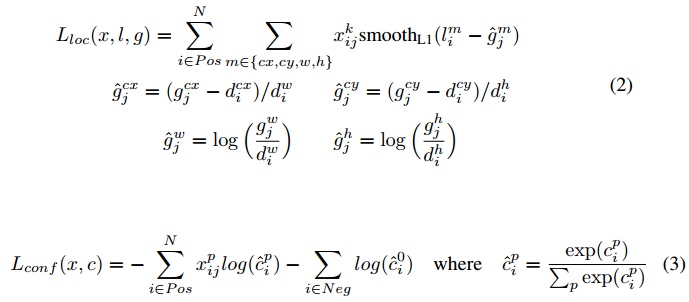
该论文是在 ImageNet 分类和定位问题上的已经训练好的 VGG16 模型中 fine-tuning 得到,使用 SGD,初始学习率为 , 冲量为 0.9,权重衰减为 0.0005,batchsize 为 32。不同数据集的学习率改变策略不同。新增加的卷积网络采用 xavier 的方式进行初始化。在预测阶段,直接预测每个 default box 的偏移以及对于每个类别相应的得分。最后通过 nms 的方式得到最后检测结果。
Default Boxes
该论文中利用不同层的 feature map 来模仿学习不同尺度下物体的检测。
- scale: 假定使用 m 个不同层的feature map 来做预测,最底层的 feature map 的 scale 值为
,最高层的为
,其他层通过下面公式计算得到
- ratio: 使用不同的 ratio值
计算 default box 的宽度和高度:
,
。另外对于 ratio = 1 的情况,额外再指定 scale 为
也就是总共有 6 种不同的 default box。
-
default box中心:上每个 default box的中心位置设置成  ,其中  表示第k个特征图的大小 。
总结
整个论文主要做了如下的工作:
- 设计了一个SSD的网络结构,比YOLO快,更加精确
- 在feature map用3*3的卷积核,预测多尺度的一系列的Box offsets和category scores
- SSD主要利用不同层的feature map,获得不同比例的图像。
- 设计了一个end-to-end的训练
- 通过实验,在不同的数据集训练,验证自己的效果的确优于其他方法。
The fundamental improvement in speed comes from eliminating bounding box proposals and the subsequent pixel or feature resampling stage.
Our improvements include using a small convolutional filter to predict object categories and offsets in bounding box locations, using separate predictors (filters) for different aspect ratio detections, and applying these filters to multiple feature maps from the later stages of a network in order to perform detection at multiple scales.
主要问题
SSD在小的目标检测效果比大目标要差,也是理所应当,小目标在top layer信息很少,提高图像的大小可以提高实验的效果。