R-FCN论文笔记
R-FCN
R-FCN是在Faster R-CNN上的一种改进,其主要贡献包括
- 将所有Conv层都进行公用于RPN和Detection Net。
- 利用Position-sensitive score maps & Position-sensitive RoI pooling来解决深层神经网络中希望目标平移不变性和detection问题中希望平移可变性的矛盾。
- 将ResNet-101这种深层网络利用到了Detection问题中。
- 将voting的思想融入到了Detection中。
其中启发的motivation是:
We argue that the aforementioned unnatural design is caused by a dilemma of increasing translation invariance for image classification vs. respecting translation variance for object detection.
网络结构
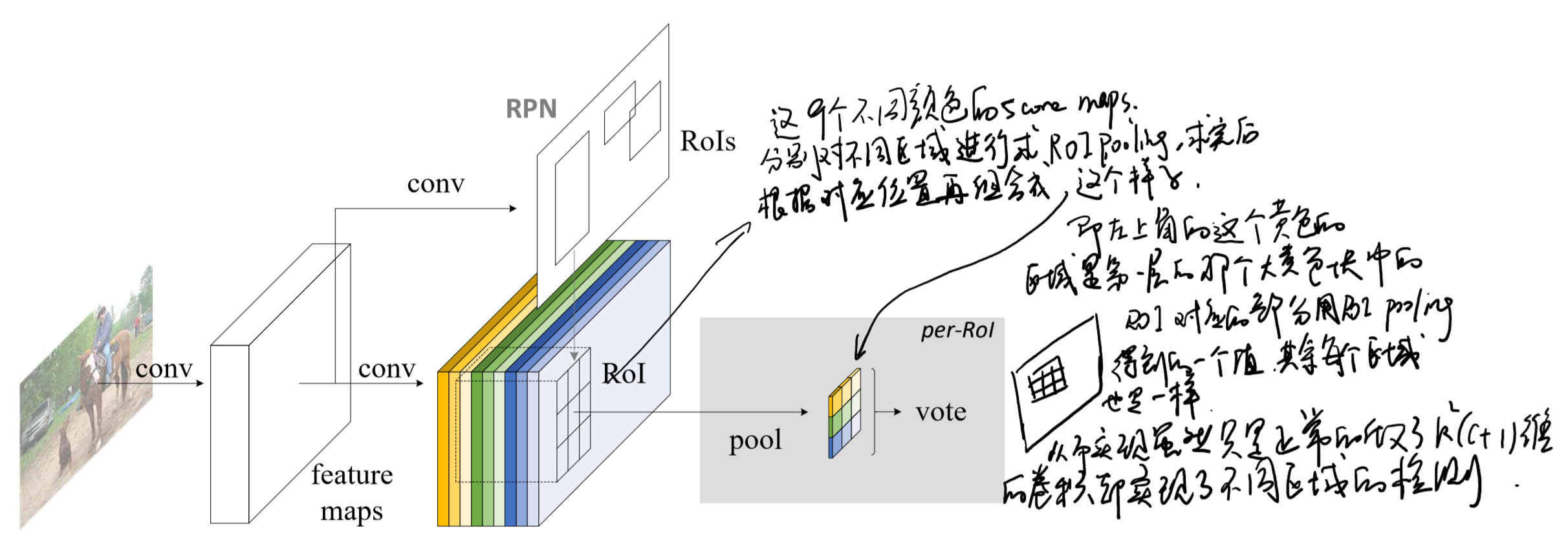
前面的base network使用了ResNet-101,去除了最后的fc层和pooling层,再接一个1*1*1024的全卷积层(降维)。在后面彩色部分就没有带weight的层了,所以保证了conv的子网络被RPN和detector都完全共享了。
k^2(C+1)的conv:
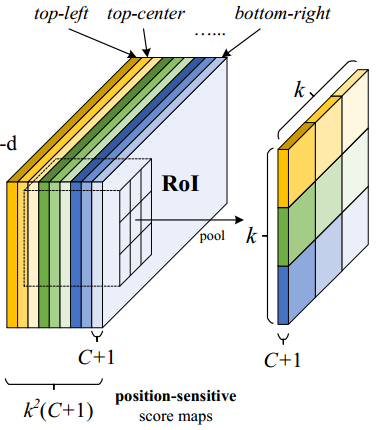
ResNet101的输出是W*H*1024,用K^2(C+1)个1024*1*1的卷积核去卷积即可得到K^2(C+1)个大小为W*H的position sensitive的score map。这步的卷积操作就是在做prediction。k = 3,表示把一个ROI划分成3*3,对应的9个位置分别是:上左(左上角),上中,上右,中左,中中,中右,下左,下中,下右(右下角),如图


k^2(C+1)个feature map的物理意义
共有k*k = 9个颜色,每个颜色的立体块(W*H*(C+1))表示的是不同位置存在目标的概率值(第一块黄色表示的是左上角位置,最后一块淡蓝色表示的是右下角位置)。共有k^2*(C+1)个feature map。每个feature map,z(i,j,c)是第i+k(j-1)个立体块上的第c个map(1<= i,j <=3)。(i,j)决定了9种位置的某一种位置,假设为左上角位置(i=j=1),c决定了哪一类,假设为person类。在z(i,j,c)这个feature map上的某一个像素的位置是(x,y),像素值是value,则value表示的是原图对应的(x,y)这个位置上可能是人(c=‘person’)且是人的左上部位(i=j=1)的概率值。
ROI pooling
就是faster RCNN中的ROI pooling,也就是一层的SPP结构。主要用来将不同大小的ROI对应的feature map映射成同样维度的特征,思路是不论对多大的ROI,规定在上面画一个n*n 个bin的网格,每个网格里的所有像素值做一个pooling(平均),这样不论图像多大,pooling后的ROI特征维度都是n*n。注意一点ROI pooling是每个feature map单独做,不是多个channel一起的。
ROI pooling的输入和输出
ROI pooling操作的输入(对于C+1个类)是k^2*(C+1)*W’ *H’(W’和H’是ROI的宽度和高度)的score map上某ROI对应的那个立体块,且该立体块组成一个新的k^2*(C+1)*W’ *H’的立体块:每个颜色的立体块(C+1)都只抠出对应位置的一个bin,把这k*k个bin组成新的立体块,大小为(C+1)*W’*H’。例如,下图中的第一块黄色只取左上角的bin,最后一块淡蓝色只取右下角的bin。所有的bin重新组合后就变成了类似右图的那个薄的立体块(图中的这个是池化后的输出,即每个面上的每个bin上已经是一个像素。池化前这个bin对应的是一个区域,是多个像素)。ROI pooling的输出为为一个(C+1)*k*k的立体块。
Voting
k*k个bin直接进行求和(每个类单独做)得到每一类的score,并进行softmax得到每类的最终得分,并用于计算损失。
整体上,把Fast R-CNN换成了先用卷积做prediction,再进行ROI pooling。由于ROI pooling会丢失位置信息,故在pooling前加入位置信息,即指定不同score map是负责检测目标的不同位置。pooling后把不同位置得到的score map进行组合就能复现原来的位置信息。 reference:R-FCN论文阅读
Training
其余的部分包括训练的目标函数,训练策略都和前人的工作基本类似,如下:
- 使用了Online Hard Example Mining(OHEM)来精心选择loss大的一些proposal
- input size 等于 600px
- loss function和faster r-cnn基本上相同
- 将ResNet-101中的步长从32减少到了16;conv5中的stride从2改成1;从而增加了score map的分辨率。
- 使用了A trous算法(Semantic Segmentation中常用的,也就是hole算法)来弥补减少的stride
Result
- R-FCN比Faster R-CNN的mAP高,同时计算速度是要更快的。
- ResNet-101层的效果是最好的
