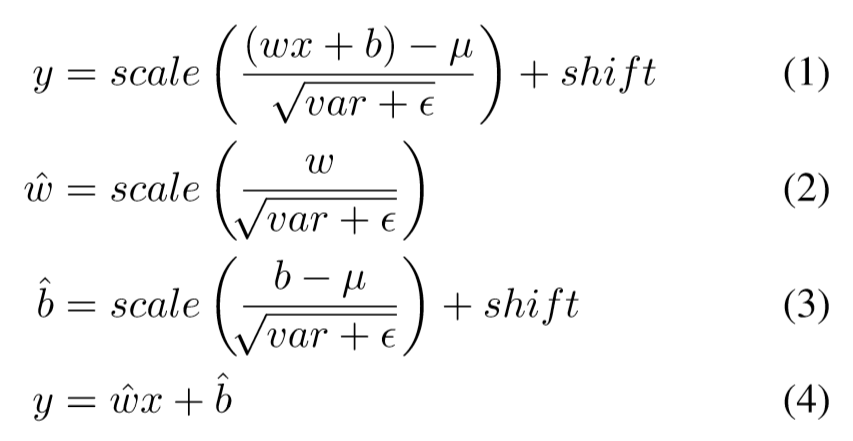FPN & DSSD论文笔记
FPN
我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
SSD、MSCNN 利用不同层的特征图进行不同尺寸的目标预测,又快又好,基于proposal的方法也借鉴了这个思路:在不同深度的特征层上预测不同尺寸的目标。
但是SSD为了预测小目标,就得把比较低的层拿出来预测,这样的话就很难保证有很强的语义特征,所以作者就想着,为什么不把高层的特征再传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。
网络结构
Pyramid scale learning
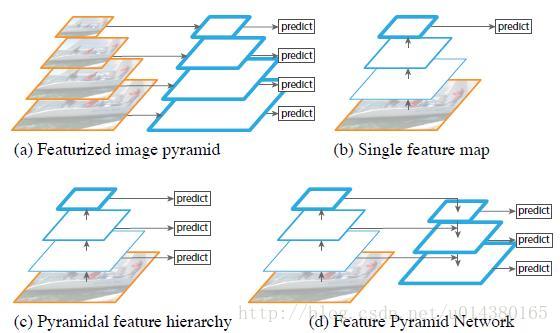
本文对过去的多种pyramid的操作进行了对比:
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
Structure
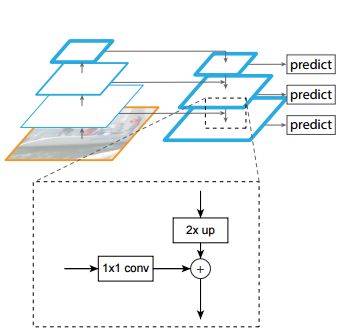
整个网络包括了正常的Bottom-Up部分和在本文中增加的Top-Down结构。FPN的Top-Down结构把每一层的channels都改成了256d,然后每一层经过一个3x3的卷积消除上采样带来的混叠效应。
虚线框可以理解成特征融合的操作,1x1的卷积有三个作用(reference:FPN + DSSD 阅读笔记):使bottom-up对应层降维至256;缓冲作用,防止梯度直接影响bottom-up主干网络,更稳定;组合特征。
上采样2x up作者采用的是nearest neighbor。加号是element-wise sum(DSSD中实验结果是element-wise product会好一点点)。
实验结果和分析
本文在RPN和Detection上都进行了测试,这里重点讲讲在Detection的测试中的一些小技巧。
由于在做detection时,每一个level的层是单独预测的,而每一层的分辨率又不一样,那么一个图片上的RoI,具体应该分配给哪一个层来处理呢?
一般的想法是直接按照尺寸来分配,但是作者采用了下面的公式:
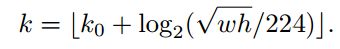
Faster RCNN用了Res-Net的,所以作者也把
设置为4;也就是说如果你的RoI的面积小于
,那么这个RoI就从
上提取特征。
分析
- 如果没有top-down的语义增强分支(仍然从不同的层输出),那么RPN的AR(average recall)会下降6%左右;
- 如果不进行特征的融合(也就是说去掉所有的1x1侧连接),虽然理论上分辨率没变,语义也增强了,但是AR下降了10%左右!作者认为这些特征上下采样太多次了,导致它们不适于定位。Bottom-up的特征包含了更精确的位置信息。
- 如果不利用多个层进行输出呢?作者尝试只在top-down的最后一层(分辨率最高、语义最强)设置anchors,仍然比FPN低了5%。需要注意的是这时的anchors多了很多,但是并没有提高AR。
- 在RPN和object detection任务中,FPN中每一层的heads 参数都是共享的,作者认为共享参数的效果也不错就说明FPN中所有层的语义都相似。
DSSD
DSSD (Deconvolution SSD) 是借鉴了MS-CNN和SSD的思想,将DeConv层连接到原始的SSD结构后,和FPN类似地得到了一个HourGlass的对称结构。再通过使用多个不同resolution和不同receptive field size的feature maps,独立的进行预测,从而实现multi-scale的目标检测。结果显示DSSD在小物体检测上有明显的提升。
网络结构
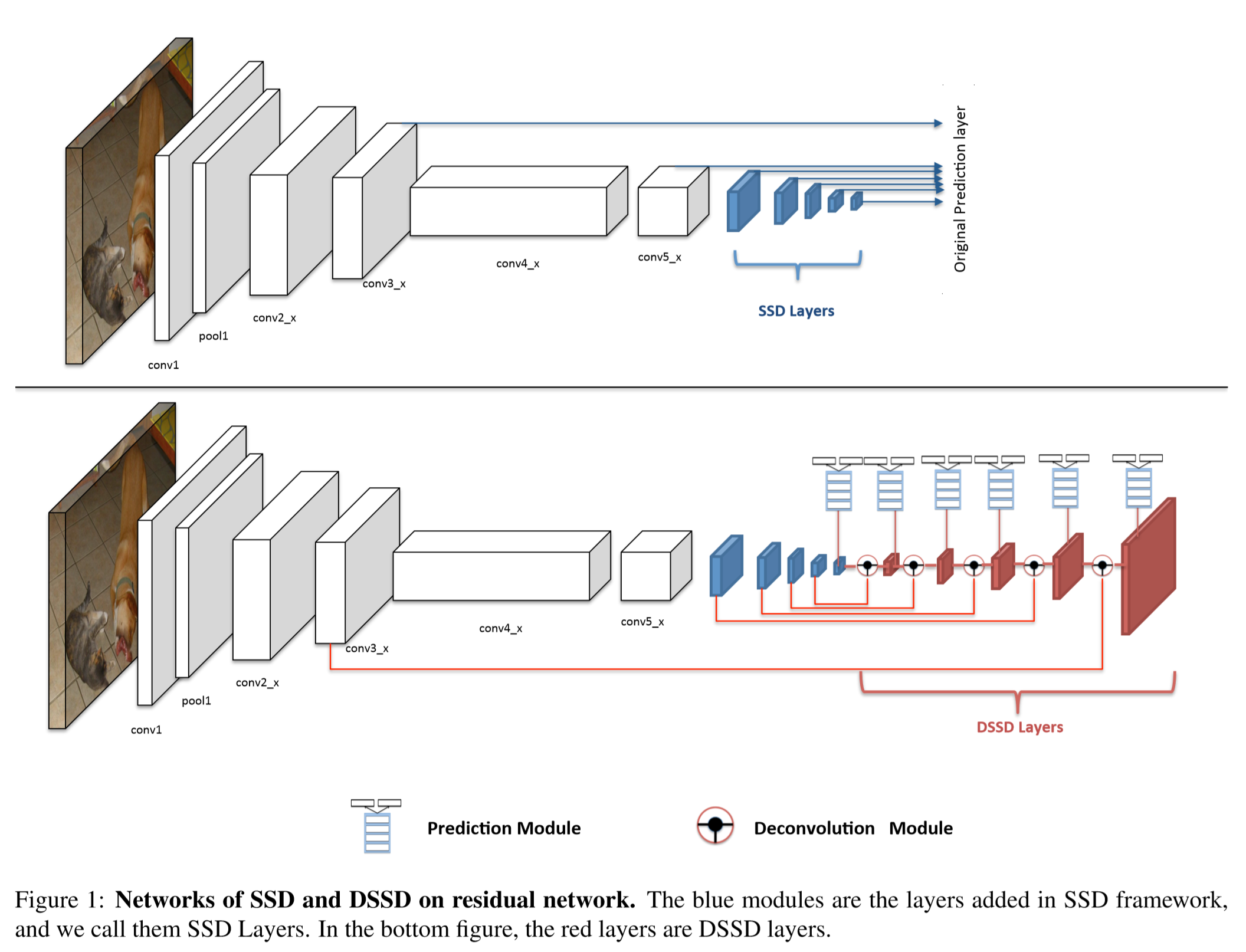
上图中上部是SSD的模型,下图是DSSD的模型。可以看到,相比于直接用各个层进行预测,DSSD在进行了DeConv之后才开始进行预测,这个Deconv由于使用了底层的信息也使用了高层的信息,所以可以通过卷积操作学习出一个合适的组合,在提高resolution的时候也保存了更高的semantic信息。
但是由于base network选择了ResNet-101,并不能像FPN一样使用简单的叠加就取得效果的提升,所以作者对整个网络进行了精心的处理,包括如下几个部分
DeConv
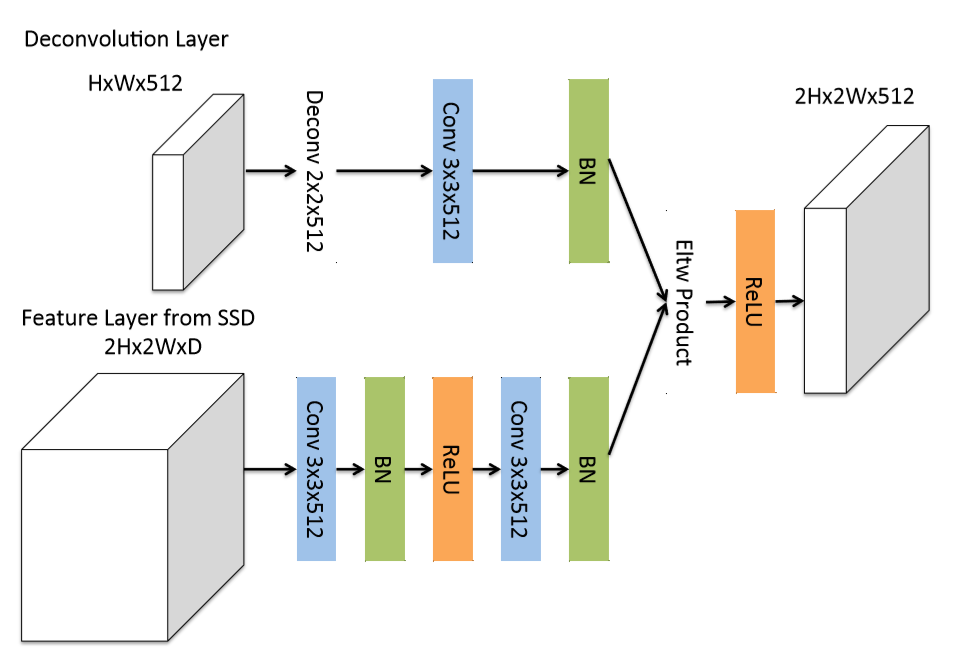
和FPN不同,这里的DeConv部分使用了较复杂的tiny network来代替简单的element-sum。因为在P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Dollr. Learning to refine object segments. In ECCV, 2016. 4 提到 “ a factored version of the deconvolution module for a refinement network has the same accuracy as a more complicated one and the network will be more efficient.”
其次,这里通过测试发现,Element-product的效果比Element-sum效果好。
Prediction Module
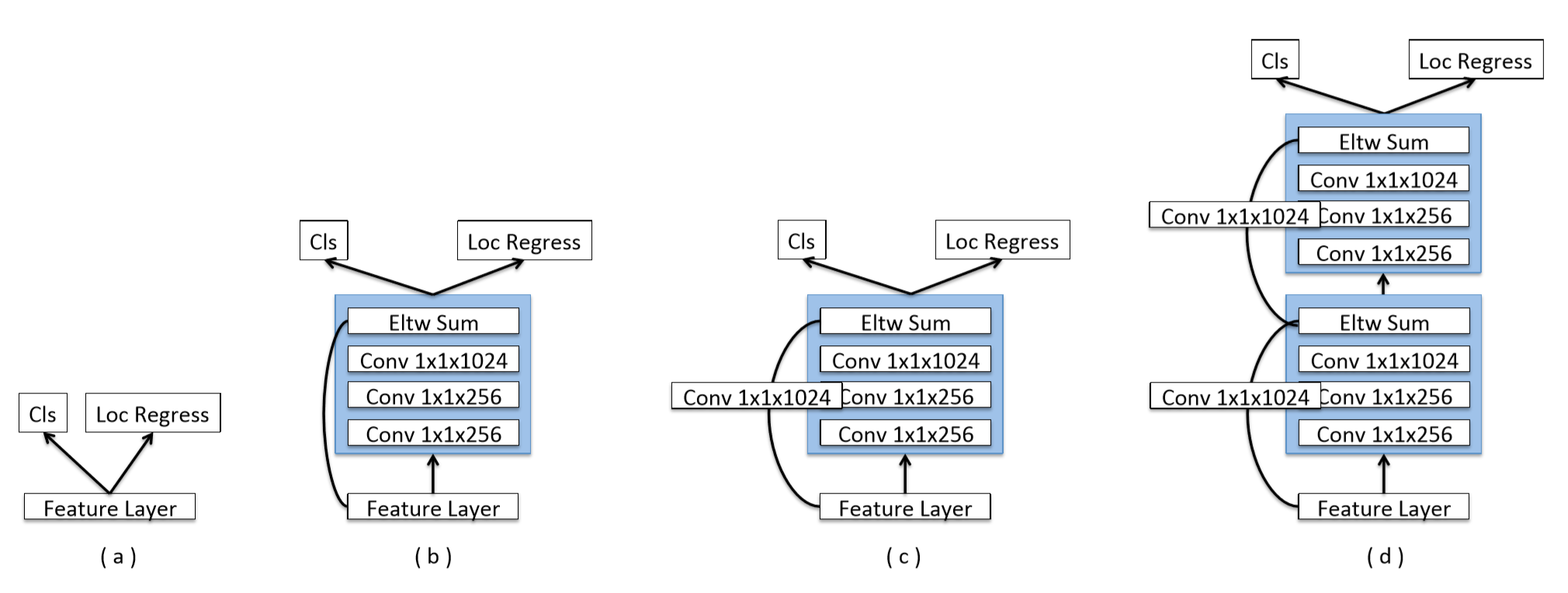
在原始的SSD中,预测部分是直接和feature map相连的,但是MS-CNN提出使用一个小的sub-network可以提升预测部分的效果。所以在本文的预测部分,选择的(c)中的结构。实验发现(d)中的双层效果并没有提升。
Training & Result
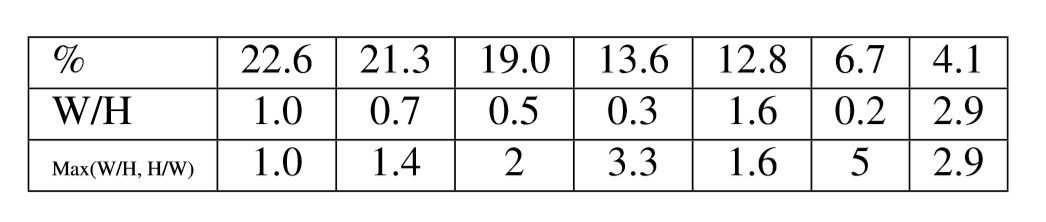
训练部分,大多的设置和SSD的相同,主要的特殊部分是通过对数据的聚类,坐着发现大多数的目标bounding box都是都是在1:3的这个比例内的,然后根据聚类的结果,增加了一个新的ratio的box(1.6:1)
训练部分,作者提出了一种Two Stage的训练策略。首先,整个网络使用训练好的SSD来初始化DSSD;第一阶段,freeze SSD的部分,仅训练新增的DeConv部分;第二阶段,fine-tunning整个网络。
但是,根据实验结果可以得出,其实仅使用第一阶段的训练效果更好。
在测试时间上,速度肯定是更慢的,主要原因有三:使用了ResNet-101,比VGG更多卷积操作;使用了多的DeConv部分;使用了更多的default box。为此,作者在测试时使用了如下的公式来替换BN层,这样使得得到1.2-1.5倍的速度。