Focal Loss论文笔记
Focal Loss (RetinaNet)
本文最主要的贡献在于对Detection问题中One-Stage模型一直比Two-Stage模型精度差的原因提出了新的思路。前人的大多工作都在修改模型,希望detection时使用更多的feature maps来实现multi-scale的检测,获取更多的feature。但是本文提出,导致这个问题的关键在于正负样本的imbalance。由于有大量的easy background data使得模型并未能学到最hard的数据,所以作者提出了一个新的Focal Loss来代替原有的Cross Entropy Loss,使得easy data的loss降低,hard data的loss提高。
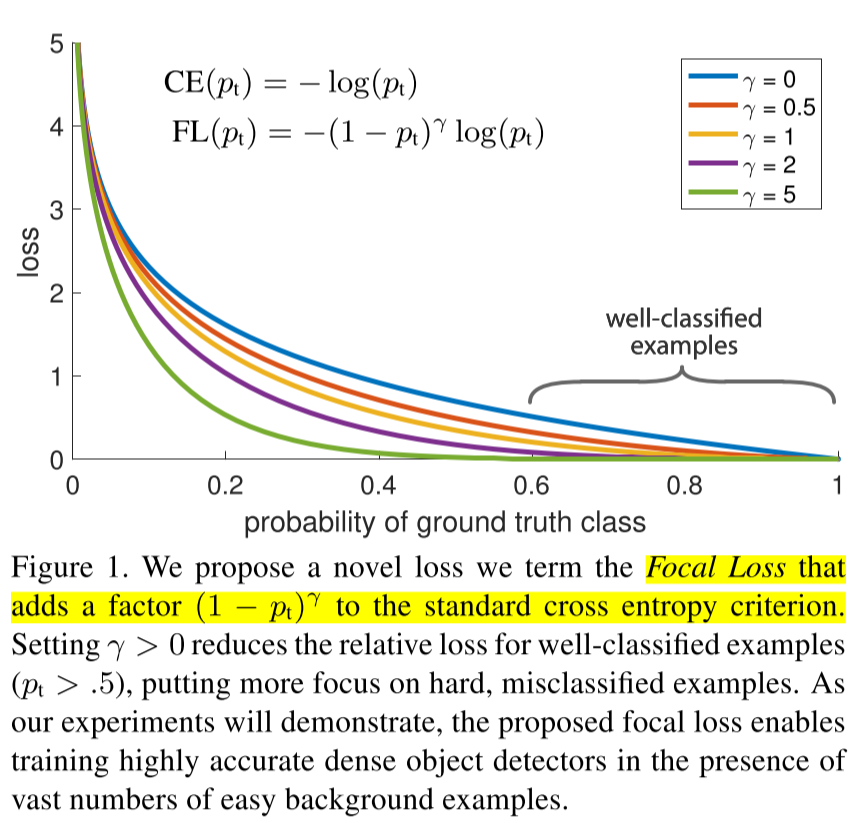
本文提出提出Single stage detector不好的原因完全在于
- 极度不平衡的正负样本比例: anchor近似于sliding window的方式会使正负样本接近1000:1,而且绝大部分负样本都是easy example,这就导致下面一个问题:
- gradient被easy example dominant的问题:往往这些easy example虽然loss很低,但由于数 量众多,对于loss依旧有很大贡献,从而导致收敛到不够好的一个结果。
所以作者使用了上述的Focal Loss。
实验中作者比较了已有的各种样本选择方式:
- 按照class比例加权重:最常用处理类别不平衡问题的方式
- OHEM:只保留loss最高的那些样本,完全忽略掉简单样本
- OHEM+按class比例sample:在前者基础上,再保证正负样本的比例(1:3)
Focal loss各种吊打这三种方式,coco上AP的提升都在3个点左右,非常显著。值得注意的是,3的结果比2要更差,其实这也表明,其实正负样本不平衡不是最核心的因素,而是由这个因素导出的easy example dominant的问题。不过比较遗憾的是,作者并没有给出OHEM会让结果变差的一个合理解释,这其实也是很值得深挖的一点。reference:https://www.zhihu.com/question/63581984/answer/210832009
结果上,最好的模型(ResNet101+FPN)做到了single model39.1 AP,其余的model在speed和accuracy之间的tradeoff也都是在efficient frontier上。