FCN
FCN阅读笔记
Fully Convolutional Network算是目前pixelwise prediction类问题的开山之作了,也是获得了CVPR 2015的best paper。文章除了应用在semantic segmentation有很好的效果,同时在前面也谈到了对于全卷积网络的一些分析。其实后面semantic segmentation的部分还好懂一些,前面Section 3的部分读的还是很吃力。
Fully Convolutional Network (对应原文第三节)
1. Convolutionalization
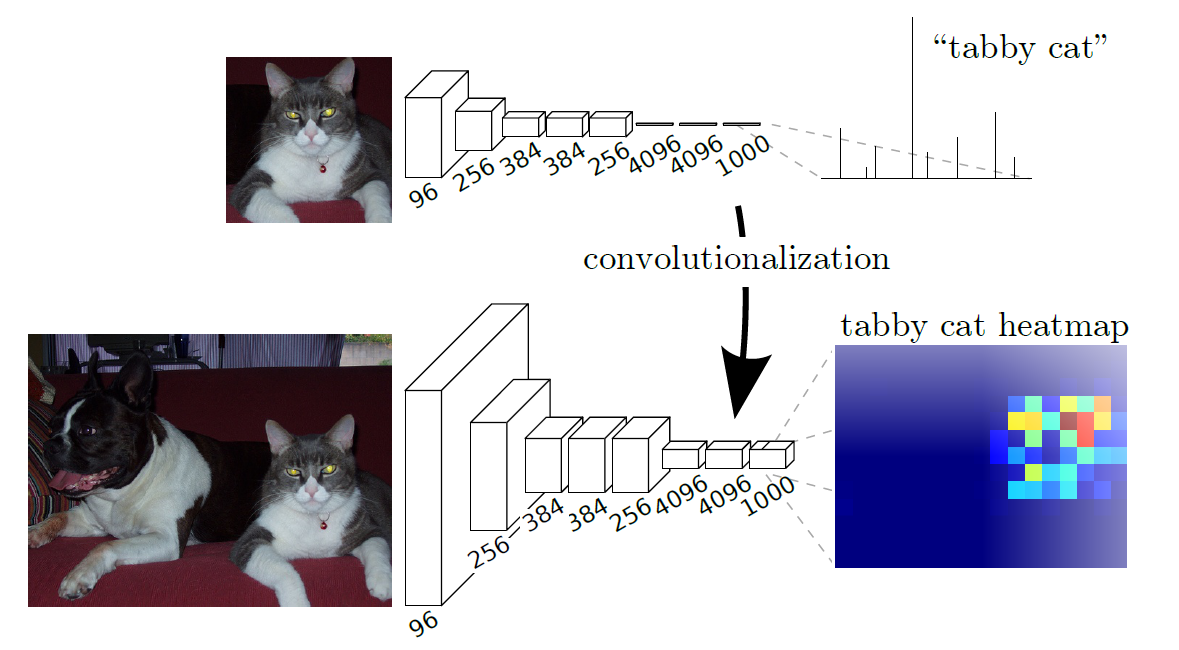
以现在的观点来看,这种将全连接层转换为卷积层的操作还是很自然的。全连接层会损失空间关系,同时输出的单一维度的输出,为此改为卷积后可以通过输出一个heatmap来对每个点进行分类,heatmap的channel维度的大小就是类别数。
2. Upsampling is backwards strided convolution
文章里面讲了一小节Shift-and-stitch的部分,这部分我看的是这里写的
对于移针法,设原图与FCN所得输出图之间的降采样因子是f,那么对于原图的每个ff的区域(不重叠),“shift the input x pixels to the right and y pixels down for every (x,y) ,0 < x,y < f." 把这个ff区域对应的output作为此时区域中心点像素对应的output,这样就对每个ff的区域得到了f^2个output,也就是每个像素都能对应一个output,所以成为了dense prediction。
这种及其暴力和粗糙的做法显然是不好的,所以作者还提到的另一种做法,叫做稀疏滤波(filter rarefaction),具体的说法还可以参考https://blog.csdn.net/happyer88/article/details/47205839
但是整体来说,肯定是都是一种不太优秀的折中的,都没有upsampling好。具体的upsampling使用的是transpose convolution,这里使用的是end-to-end的可学习的transpose convolution。具体的反卷积的部分可以参考很多别的资料学习一下。
3. Whole image training
文中提到说,patchwise training方法是为了减少信息的冗余和依赖,从而保证数据平衡,这相当于加了一个mask在loss上,那么其实是一种loss sampling,但是这种做法效率很低,重复计算很多,这完全可以通过给loss加上权重或者直接采样完成。这部分可以参考这里的一个回答[patch-wise training and fully convolutional training in FCN
Semantic Segmentation
Skip strategy
除了卷积化的部分,FCN还采取了skip策略,前面层的输出通过一个1*1的卷积+最后一层输出upsample之后的结果得到最终的预测feature map,然后再upsample为输入的尺寸。
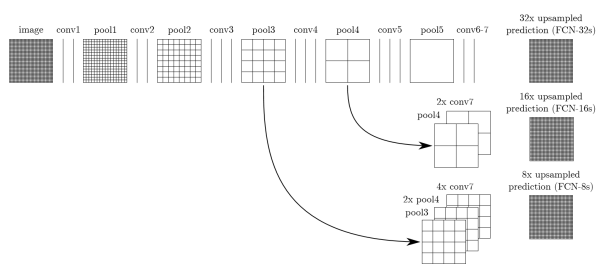
这里最后一层的upsample是固定为双线性插值的参数的,前面几个upsample层是可学习的。
其他
- 从FCN-32到FCN-16的提升比较明显,再到FCN-8的时候就不是很明显了
- GoogleNet的效果不如VGG-16
- 使用了8498张图片
- data augmentation的作用不大
- patch sampling在收敛速度上没什么效果而且由于需要生成大量patch速度还很慢
- 代码上来看,在一开始预测的时候还增加了100的padding,这是因为如果不进行padding操作,对于长或宽不超过192像素的图片是没法处理的 (参考:https://zhuanlan.zhihu.com/p/22976342)