DeconvNet & SegNet
DeconvNet & SegNet
DeconvNet和SegNet都是使用encoder-decoder结构构件的模型,都是在upsampling这部分做出了创新,但是相比来说SegNet更加实用一些,这里分别具体介绍一下两个模型,后面再做一些比较。
DeconvNet
FCN里面对各层的输出只做了一次deconvolution,然后再整体做了双线性插值。但是其实这种可学习的上采样完全可以通过堆叠不断得到最终的输出,从而行程一种对称的网络结构。
同时文章还提出FCN所对应的感知野大小固定,若需要检测的物体大小与感知野相差较大(小物体,特大物体)时,效果比较差。
DeconvNet的网络结构如下,其中BN层对于网络的学习很关键;值得注意的是这里没有去掉FC层,所以参数量还是很大。
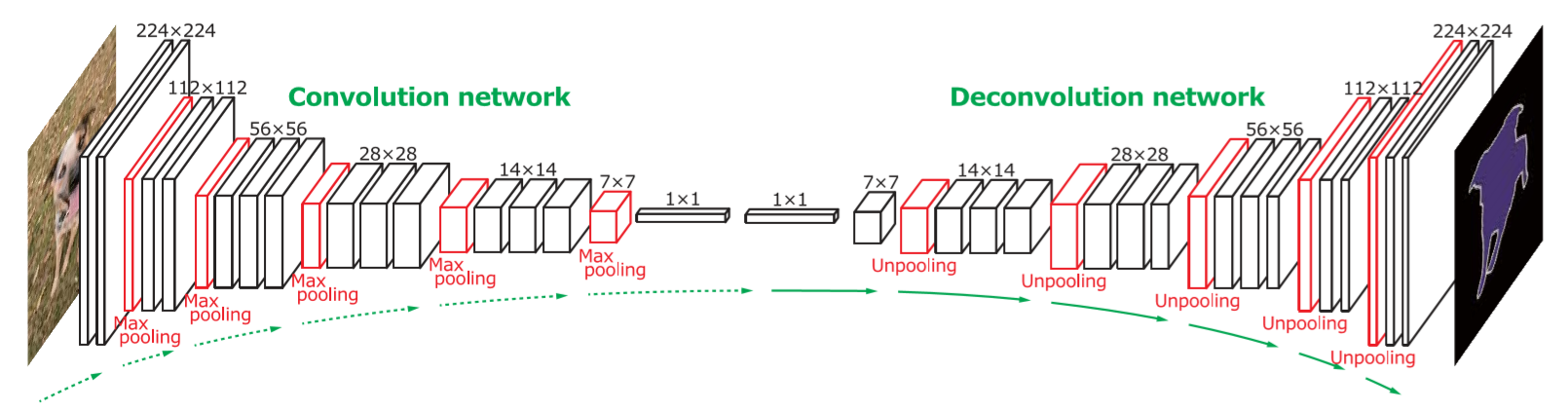
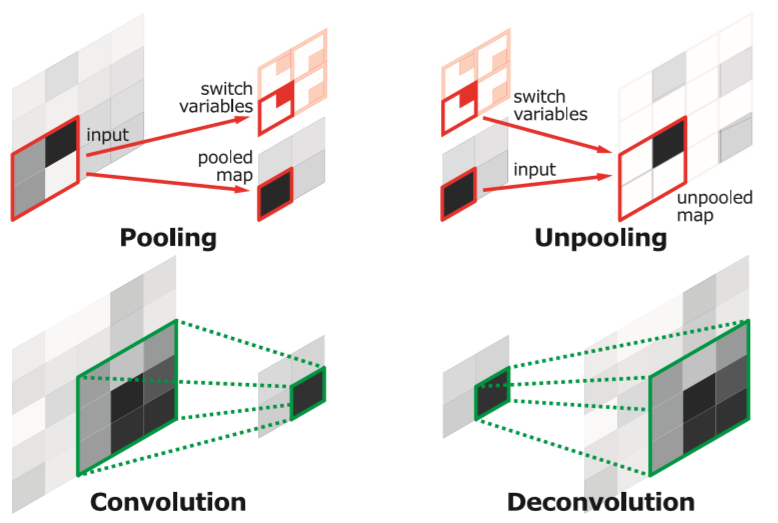
其中decoder部分主要由两种操作构成,分别是unpooling和deconvolution。unpooling这部分通过记录encoder部分对应的max pooling的indice从而能够有针对性的unpooling,这一步作者表示是获取example-specific结构;unpooling的结果是稀疏的,使用deconvolution可以进行学习,从而获取class-specific shapes,为了保证输出输出的size一样,这里是对deconvolution的输出再进行crop(这里和目前比较普遍的先pad再conv的思想比较不一样)。
 、、
、、
在training和test这一步,DeconvNet的特殊之处在于没有whole-image training,而是在每张图里面crop出很多只包含单个目标的sub-image,对这些子块进行instance-wise segmentation,再将各个的结果ensemble成最终的结果。
DeconvNet为了提高学习的效果,1)采用了two-stage的训练方法,先学习简单sample,再学习challenge examples;2)增加了CRF后处理;3)与FCN做模型融合。
SegNet
与DeconvNet相比,SegNet做了更多性能和内存、速度上的权衡。首先SegNet去掉了FC层,所以参数量降低到了1/10的程度,同时在Upsampling的时候,是使用的conv层而非Deconv层。
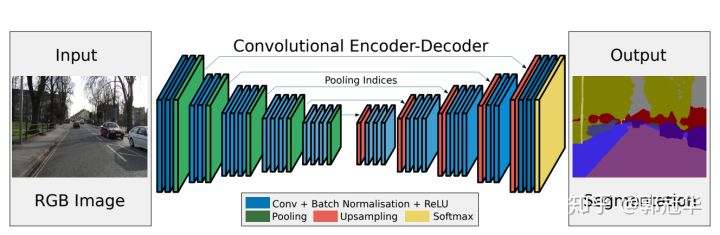
- 把本文提出的架构和FCN、DeepLab-LargeFOV、DeconvNet做了比较,这种比较揭示了在实现良好分割性能的前提下内存使用情况与分割准确性的权衡。
- SegNet的主要动机是场景理解的应用。因此它在设计的时候考虑了要在预测期间保证内存和计算时间上的效率。
- 定量的评估表明,SegNet在和其他架构的比较上,时间和内存的使用都比较高效。
文中对不同的decoder组件做了对比分析
- Bilinear-Interpolation : 双线性插值上采样。
- SegNet-Basic: 4(encodes[conv+bn+relu+maxpooling] + decoders[conv+bn]) ,kenel size: 77。
- SegNet-Basic-SingleChannelDecoder: decoder采用单通道滤波器,可以有效减少参数数量。
- SegNet-Basic-EncoderAddition: 将decoder与encoder对应的特征图相加。
- FCN-Basic:与SegNet-Basic具有相同的encoders,但是decoders采用FCN的反卷积方式。
- FCN-Basic-NoAddition:去掉特征图相加的步骤,只学习上采样的卷积核。
- FCN-Basic-NoDimReduction: 不进行降维。
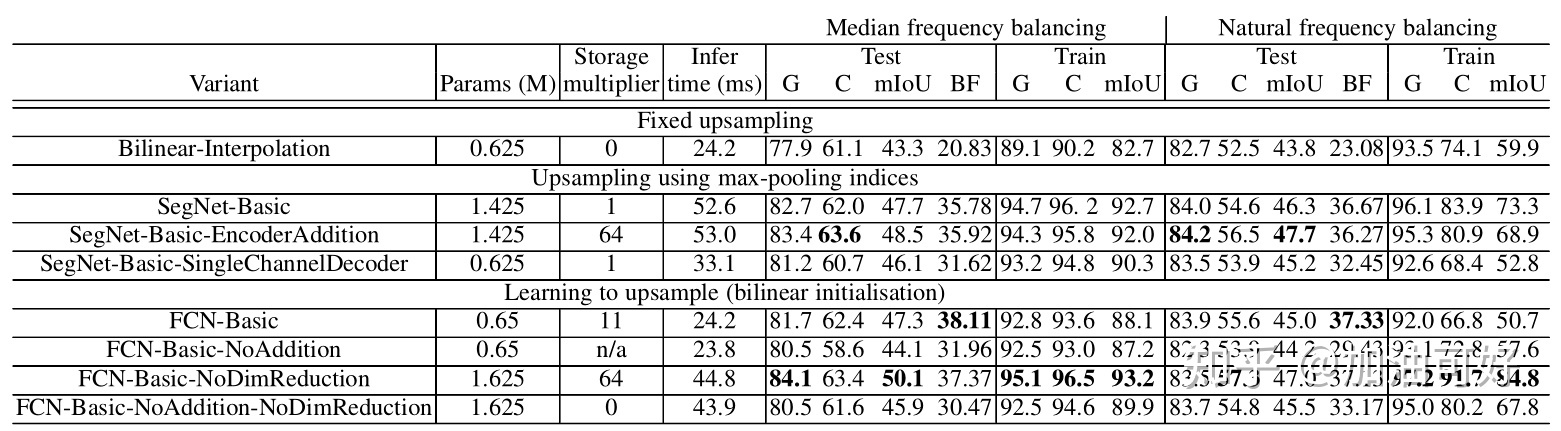
通过上表分析,可以得到如下分析结果:
- bilinear interpolation 表现最差,说明了在进行分割时,decoder学习的重要性。
- SegNet-Basic与FCN-Basic对比,均具有较好的精度,不同点在于SegNet存储空间消耗小,FCN-Basic由于feature map进行了降维,所以时间更短。
- SegNet-Basic与FCN-Basic-NoAddition对比,两者的decoder有很大相似之处,SegNet-Basic的精度更高,一方面是由于SegNet-Basic具有较大的decoder,同时说明了encoder过程中低层次feature map的重要性。
- FCN-Basic-NoAddition与SegNet-Basic-SingleChannelDecoder:证明了当面临存储消耗,精度和inference时间的妥协的时候,我们可以选择SegNet,当内存和inference时间不受限的时候,模型越大,表现越好。
作者总结到:
- encoder特征图全部存储时,性能最好。 这最明显地反映在语义轮廓描绘度量(BF)中。
- 当限制存储时,可以使用适当的decoder(例如SegNet类型)来存储和使用encoder特征图(维数降低,max-pooling indices)的压缩形式来提高性能。
- 更大的decoder提高了网络的性能。