UNet
#UNet
前面介绍过DeconvNet和SegNet,都是在upsampling这一步做出了一定的改进,包括记录pooling的index,使用conv或者deconv进行学习,这种encoder-decoder的做法取得了不错的效果。而UNet这篇也是早期(2015年)对encoder-decoder这种对称结构网络的一种尝试创新。我们知道FCN在预测的时候结合了底层信息和高层信息,虽然只有一次可学习的上采样。UNet就是将这种不同层的信息结合的思想和Encoder-Decoder结构结合了起来,使得能够在decoder每次上采样的时候将对应底层的信息融合进来,这种skip-connection的策略得到了很好的效果。
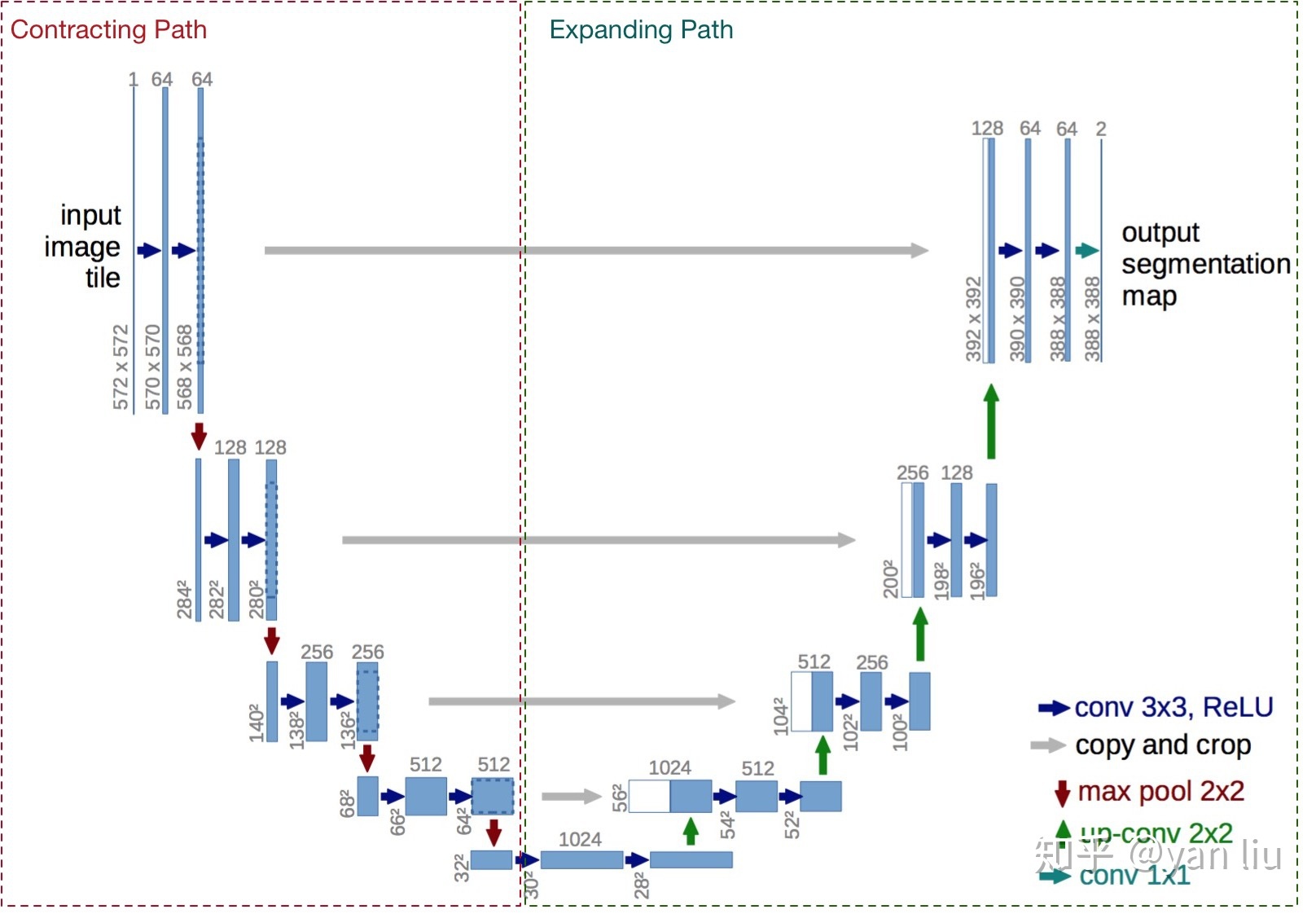
网络的输入是一张572*572的边缘经过镜像操作的图片,网络的左侧(红色虚线)是由卷积和Max Pooling构成的一系列降采样操作,论文中将这一部分叫做压缩路径(contracting path)。压缩路径由4个block组成,每个block使用了3个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2,因此有了图中所示的Feature Map尺寸变化。最终得到了尺寸为32*32的Feature Map。
网络的右侧部分(绿色虚线)在论文中叫做扩展路径(expansive path)。同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即图1中左侧虚线部分)。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的Feature Map的尺寸是388*388 。由于该任务是一个二分类任务,所以网络有两个输出Feature Map。
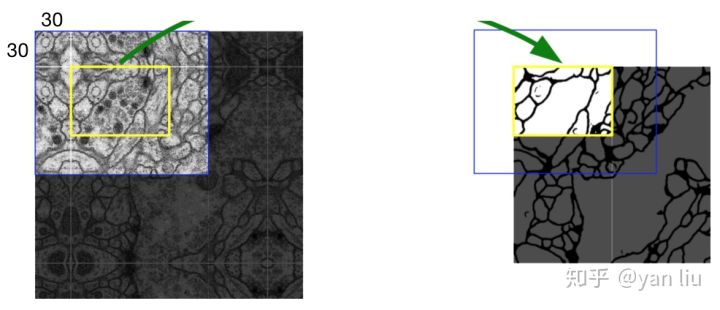
数据集的原始大小是512*512的,为了能更好的处理图像的边界像素,U-Net使用了镜像操作(Overlay-tile Strategy)来解决该问题。镜像操作即是给输入图像加入一个对称的边,那么边的宽度是多少呢?一个比较好的策略是通过感受野确定。因为有效卷积是会降低Feature Map分辨率的,但是我们希望512*512的图像的边界点能够保留到最后一层Feature Map。所以我们需要通过加边的操作增加图像的分辨率,增加的尺寸即是感受野的大小,也就是说每条边界增加感受野的一半作为镜像边。
根据图1中所示的压缩路径的网络架构,我们可以计算其感受野:
这也就是为什么U-Net的输入数据是 的。572的卷积的另外一个好处是每次降采样操作的Feature Map的尺寸都是偶数,这个值也是和网络结构密切相关的。
那么该怎样设计损失函数来让模型有分离边界的能力呢?U-Net使用的是带边界权值的损失函数:
其中 是损失函数,
是像素点的标签值,
是像素点的权值,目的是为了给图像中贴近边界点的像素更高的权值。
其中 是平衡类别比例的权值,
是像素点到距离其最近的细胞的距离,
则是像素点到距离其第二近的细胞的距离。
和
是常数值,在实验中
,
。