从ROIPool到PreciseRoIPooling
#从ROIPool到PreciseRoIPooling
在目标检测和实例分割等方法中,都包含了 ROI 区域的生成这个步骤。目前基于anchor的方法里,都对在原图上的 ROI 区域有两步操作:
- 首先将原图大小的ROI映射到backbone网络输出的feature map上(由于存在subsampling,feature map上对应到原图的stride一般是16或者32);
- 第二步是通过ROI pooling将不同尺寸的feature map输出到固定的大小(一般是7*7或者14*14)
在这个过程中就存在了两步可能出现量化操作(也就是取整)的情况,这也就会带来点坐标的误差。从最开始的ROI Polling中并不处理这两个错误,到最新的PreciseRoIPooling完全解决这个错误,这期间有几个典型的改进方法,这里就对这一系列方法进行一个梳理。具体包括ROI Pooling,ROI Wrap,ROI Align,Precise ROI Pooling。
ROI Pooling
这个方法是最早出现在Faster RCNN中,但是其实这个思想是从SPP Net中吸收过来的。这里面的做法就是我上面说的两步基础操作。具体来说,有两个主要的缺点:
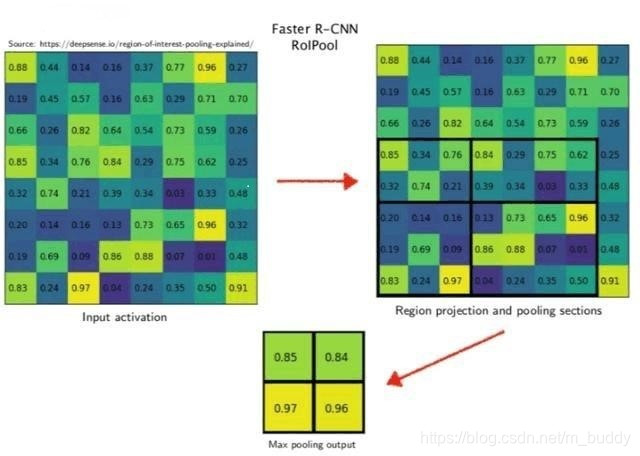
量化误差
举个例子来说,在该网络中假设使用的backbone的feature stride=16,且测试图像中的一个边界框的大小为400*300。 1)首先计算对应feature map上图的大小,那么在特征图上的大小就是200/16*150/16=25*18.75,注意这个时候出现小数了。那么就需要对其进行第一次量化操作,得到的特征图上大小为25*18。 2)得到Pooling结果。最后的RoI Pooling的输出是固定的为7*7,那么就要对这个特征图进行划分,那么划分出来的每一块的大小就是25/7*18/7=3.57*2.57。小数又来了,那么取整吧,这是第二次量化操作,块的区域就变成了3*2,然后再在这个区域上做max pooling得到最后的结果。
所以很大的误差是来自于量化过程,量化误差不断积累就变得很大了。
离散化
由于 ROI 区域中的像素是离散化的,没有梯度的更新,不能进行训练的调节。
ROI Wrap
该Pooling方法比前面提到的Pooling方法稍微好一些。该方法出现在Instance-aware Semantic Segmentation via Multi-task Network Cascades中。这里主要的改进是第二步骤,也就是从原图切换回feature map这个步骤是没有改的,但是在做ROI Pooling的时候,需要输出到固定的7*7的大小的时候,使用了等分,利用了双线性插值。
还是以上面的例子,还是两个步骤:
1)corp操作。边界框在对应feature map上的大小为200/16*150/16=25*18.75 ,这里需要像之前的方法一样对其进行第一次量化操作,得到的特征图上大小为25*18。
2)warp操作。这里使用的是双线性差值算法,使corp操作的特征图变化到固定的尺度上去,比如14∗14,这样再去做Pooling得到固定的输出。这里的坐标就是连续的了,不会存在量化误差。
这里值得一提的一个优点是有梯度的传导,Roi Warp中输入的ROI的区域的大小可以不定,输出的crop后的区域大小需要预先设定好。
ROI Align
这种Pooling方法是在Mask RCNN中被采用的,这相比之前的方法其内部完全去掉了量化操作,取而代之的线性操作,使得网络特征图中的点都是连续的。从而提升了检测的精确度。
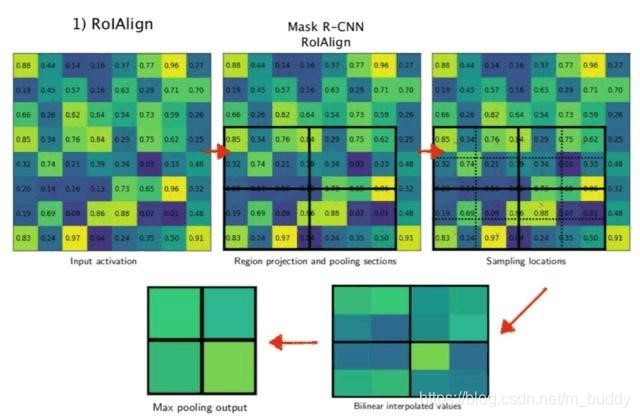
还是以上面的例子,ROI Align的具体步骤如下:
1)得到对应feature map中对应的区域。这里可以算出对应的区域大小为200/1*150/16=25*18.75 ,这个通过双线性差值计算的得到。这就是这一部分的结果了,不会对其进行量化操作。
2)得到Pooling结果。假设Pooling的固定输出为7*7,那么每个块得到的大小是25/7*18.75/7=3.57*2.65。对于这样的一个块(bin),假设在其中选择N(比如N=4=2*2)个采样点,那么每个采样点的值也是可以通过双线性差值得到,这样也是连续的。
因而相比前面的两个算法,其内部实现并没有存在量化的操作,也就没有因为量化而带来的误差。这就使得其检测精确度进一步提升。同时,对每一个bin内部的N个插值的像素使用双线性插值进行跟新,有梯度的传导。
缺点
- ROI区域中的每个bin区域中引入了新的参数,即需要插值的点的数目N。并且这个N是预先设定的,无法根据feature map做自适应调整。
- 这N个点的梯度只与其上下左右4个整数位置的像素点有关,而不是整个区域的像素点都有梯度的传递。
这里的缺点主要就是对于每个bin块中的操作是死板的,具体操作如下如所示:

这里无论feature map的大小,都是找其中一个bin里面的四个点然后求max pooling。
Precise ROI Pooling
这个方法出自论文IoU-Net,《Acquisition of Localization Confidence for Accurate Object Detection》

整体思路就是对一个bin内部进行全部连续的取值求值,使用average pooling代替取点在max pooling的做法。这里对于一个bin,整个区域的像素值通过求积分得到,所以,所有的像素值都有梯度的传递。

对于一个小的bin区域,根据内部整数值点的值,就可以利用双线性插值得到整个图的值。IC函数计算每一个连续的x,y方向的偏移的乘积,在1个像素以内的偏移,使用该像素(i,j)计算,即该像素上下左右1个像素以内的区域都会被计算到。超过一个像素的偏移的,使用下一个整数像素点(i+1,j)或者(i,j+1)计算。然后该偏移的乘积和(i,j)的像素值wij乘积得到f(x,y)。从(x1, y1)到(x2, y2)对f(x,y)求积分,即可以得到整个bin区域的像素的和,然后求平均,就得到该bin区域的输出。最终每一个bin区域都输出1个数值,形成最终的7*7输出的feature map。
总结

参考: